Acknowledgments & References
Abstract
Natural language is perhaps the most versatile and intuitive way for humans to communicate tasks to a robot.
Prior work on Learning from Play (LfP) provides a simple approach for learning a wide variety of robotic behaviors from general sensors. However, each task must be specified with a goal image—something that is not practical in open-world environments.
In this work we present a simple and scalable way to condition policies on human language instead.
We extend LfP by pairing short robot experiences from play with relevant human language after-the-fact.
To make this efficient, we introduce multicontext imitation, which allows us to train a single agent to follow image or language goals, then use just language conditioning at test time.
This reduces the cost of language pairing to less than 1% of collected robot experience, with the majority of control still learned via self-supervised imitation.
At test time, a single agent trained in this manner can perform many different robotic manipulation skills in a row in a 3D environment, directly from images, and specified only with natural language (e.g. "open the drawer...now pick up the block...now press the green button...") (video). Finally, we introduce a simple technique that transfers knowledge from large unlabeled text corpora to robotic learning.
We find that transfer significantly improves downstream robotic manipulation. It also allows our agent to follow thousands of novel instructions at test time in zero shot, in 16 different languages. See videos of our experiments below.
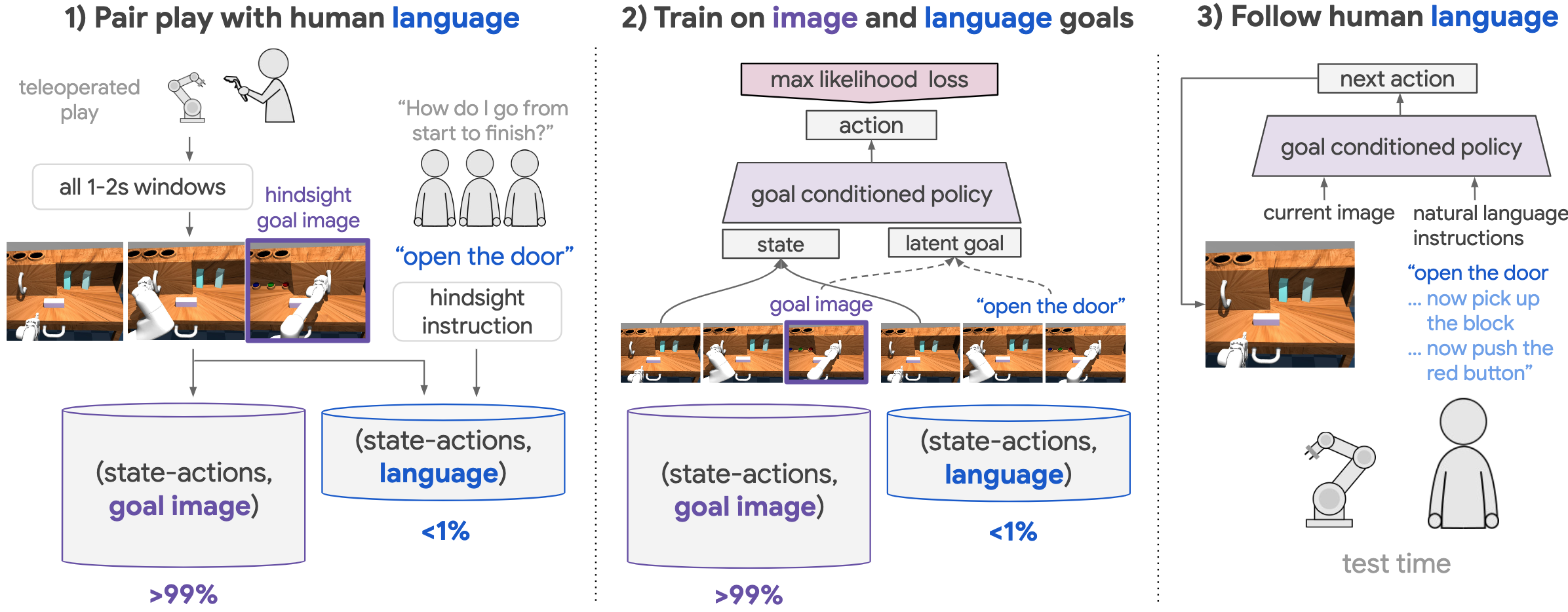 Figure 1. Learning to follow natural language instructions from play: 1) First, relabel teleoperated play into many image goal examples. Next, pair a small amount of play with hindsight instructions, yielding language goal examples. 2) Multicontext imitation: train a single policy on both image and language goals. 3) Test time: A single agent performs many skills in a row, directly from images, specified only in natural language.
Figure 1. Learning to follow natural language instructions from play: 1) First, relabel teleoperated play into many image goal examples. Next, pair a small amount of play with hindsight instructions, yielding language goal examples. 2) Multicontext imitation: train a single policy on both image and language goals. 3) Test time: A single agent performs many skills in a row, directly from images, specified only in natural language.
1. Introduction
A long-term motivation in robotic learning is the idea of a generalist robot—a single agent that can solve many tasks in everyday settings, using only general onboard sensors. A fundamental but less considered aspect, alongside task and observation space generality, is general task specification: the ability for untrained users to direct agent behavior using the most intuitive and flexible mechanisms. Along these lines, it is hard to imagine a truly generalist robot without also imagining a robot that can follow instructions expressed in natural language.
More broadly, children learn language in the context of a rich, relevant, sensorimotor experience . This motivates the long-standing question in artificial intelligence of embodied language acquisition : how might intelligent agents ground language understanding in their own embodied perception? An ability to relate language to the physical world potentially allows robots and humans to communicate on common ground over shared sensory experience—something that could lead to much more meaningful forms of human-machine interaction.
Furthermore, language acquisition, at least in humans, is a highly social process. During their earliest interactions, infants contribute actions while caregivers contribute relevant words. While we cannot speculate on the actual learning mechanism at play in humans, we are interested in what robots can learn from similar paired data. In this work, we ask: assuming real humans play a critical role in robot language acquisition, what is the most efficient way to go about it? How can we scalably pair robot experience with relevant human language to bootstrap instruction following?
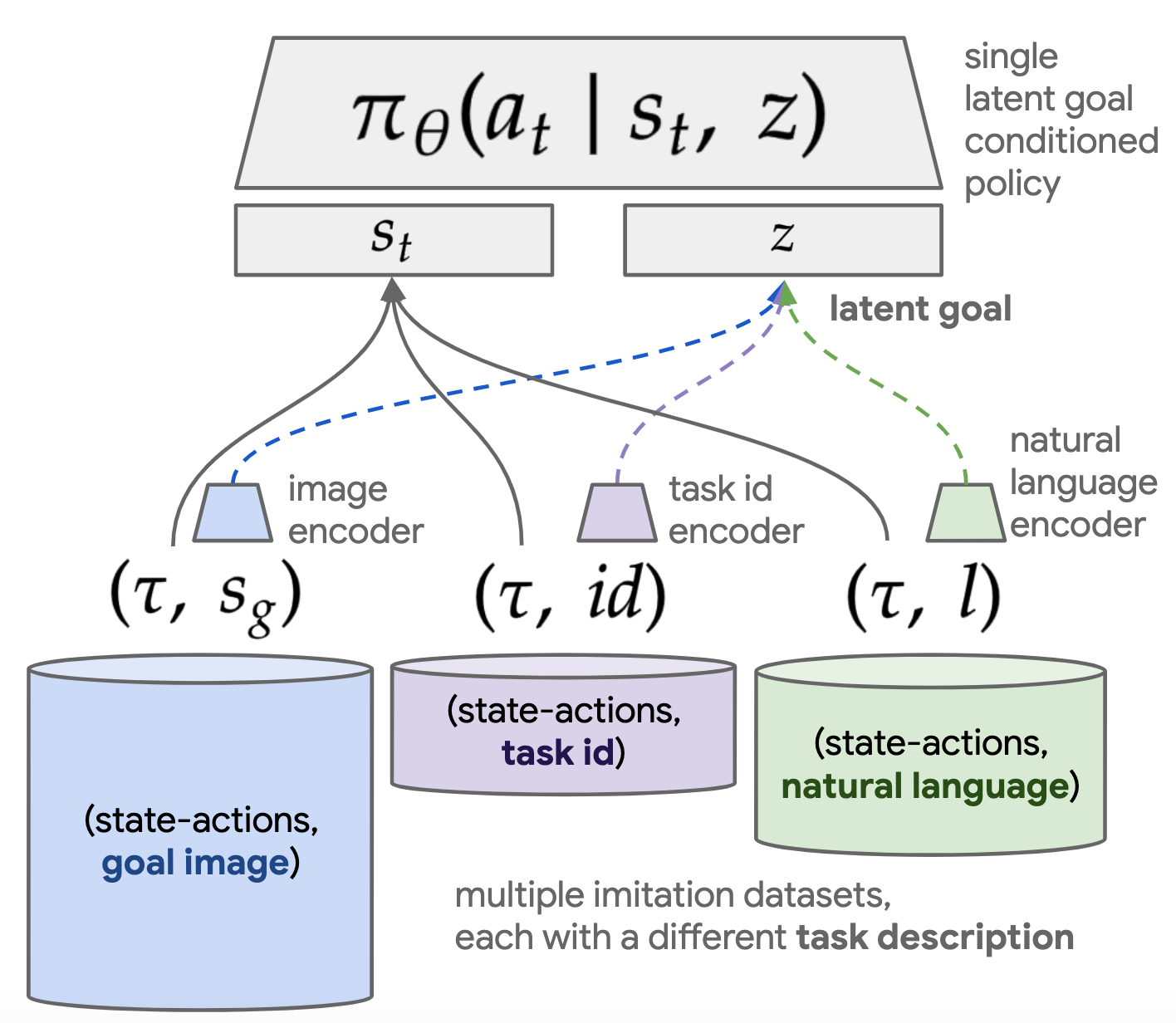 Figure 2. Multicontext Imitation Learning:
We introduce Multicontext Imitation Learning (MCIL), a simple generalization of contextual imitation learning to multiple heterogeneous contexts. An increasingly typical scenario in imitation learning is one where we have multiple imitation datasets, each with a different task description (e.g. goal image, task id, natural language, video demonstration, etc.) and different cost of collection. MCIL trains: 1) a single latent goal conditioned policy over all datasets, and 2) a set of encoders, one per dataset, each responsible for mapping a particular task description to the shared latent space.
Figure 2. Multicontext Imitation Learning:
We introduce Multicontext Imitation Learning (MCIL), a simple generalization of contextual imitation learning to multiple heterogeneous contexts. An increasingly typical scenario in imitation learning is one where we have multiple imitation datasets, each with a different task description (e.g. goal image, task id, natural language, video demonstration, etc.) and different cost of collection. MCIL trains: 1) a single latent goal conditioned policy over all datasets, and 2) a set of encoders, one per dataset, each responsible for mapping a particular task description to the shared latent space.
Even simple instruction following, however, poses a notoriously difficult learning challenge, subsuming many long-term problems in AI .
For example, a robot presented with the command "sweep the block into the drawer” must be able to relate language to low-level perception (what does a block look like? what is a drawer?). It must perform visual reasoning (what does it mean for the block to be in the drawer?). Finally, it must solve a complex sequential decision problem (what commands do I send to my arm to "sweep"?). We note these questions cover only a single task, whereas the generalist robot setting demands single agents that perform many.
In this work, we combine the setting of open-ended robotic manipulation with open-ended human language conditioning. There is a long history of work studying instruction following (survey ). Prior work typically studies restricted observation spaces (e.g. games , 2D gridworlds ), simplified actuators, (e.g. binary pick and place primitives ), and synthetic language data . We study the first combination, to our knowledge, of 1) human language instructions, 2) high-dimensional continuous sensory inputs and actuators, and 3) complex tasks like long-horizon robotic object manipulation. The test time scenario we consider is a single agent that can perform many tasks in a row, each specified by a human in natural language. For example, "open the door all the way to the right...now pick up the block...now push the red button...now close the door". Furthermore, the agent should be able to perform any combination of subtasks in any order. We refer to this as the "ask me anything" scenario (Figure 1, step 3), which tests three important aspects of generality: general-purpose control, learning from onboard sensors, and general task specification.
Prior work on Learning from Play (LfP) provides a simple starting point for learning general-purpose skills from onboard sensors: first cover state space with teleoperated "play" data, then use relabeled imitation learning to distill many reusable behaviors into a goal-directed policy. However, like other methods that combine relabeling with image observations , LfP requires that tasks be specified using a goal image to reach. While trivial in a simulator, this form of task specification is often impractical in open-world environments.
In this work, we present a simple approach that extends LfP to the natural language conditioned setting. Figure 1 provides an overview, which has four main steps:
-
Cover the space with teleoperated play (Figure 1, step 1): Collect a teleoperated "play" dataset. These long temporal state-action logs are automatically relabeled into many short-horizon demonstrations, solving for image goals.
-
Pair play with human language (Figure 1, step 1): Typical setups pair instructions with optimal behavior. Instead, we pair any behavior from play after-the-fact with optimal instructions, a process we call Hindsight Instruction Pairing. This collection method is the first contribution of this paper. It yields a dataset of demonstrations, solving for human language goals.
-
Multicontext imitation learning (Figure 1, step 2): We train a single policy to solve image or language goals, then use only language conditioning at test time. To make this possible, we introduce Multicontext Imitation Learning (Figure 2). This is the second contribution of this paper. This approach is highly data efficient. It reduces the cost of language pairing to less than 1% of collected robot experience to enable language conditioning, with the majority of control still learned via self-supervised imitation.
-
Condition on human language at test time (Figure 1, step 3): At test time, our experiments show that a single policy trained in this manner can perform many complex robotic manipulation skills in a row, directly from images, and specified entirely with natural language (see video)
Finally, we study transfer learning from unlabeled text corpora to robotic manipulation. We introduce a simple transfer learning augmentation, applicable to any language conditioned policy. We find that this significantly improves downstream robotic manipulation. This is the first instance, to our knowledge, of this kind of transfer. Importantly, this same technique allows our agent to follow thousands of novel instructions in zero shot, across 16 different languages. This is the third contribution of this work.
Video 2: Following out-of-distribution instructions in zero shot, in 16 languages.
Robotic learning from general sensors.
In general, learning complex robotic skills from low-level sensors is possible, but requires substantial human supervision. Two of the most successful approaches are imitation learning (IL) and reinforcement learning (RL) . IL typically requires many human demonstrations to drive supervised learning of a policy. In RL, supervision takes the form of a well-shaped hand-designed reward to drive autonomous trial and error learning. Designing reward functions in open-world environments is non-trivial, requiring either task-specific instrumentation or learned perceptual rewards . Additionally, RL agents face difficult exploration problems , often requiring hand-designed exploration strategies or even human demonstrations as well . Finally, conventional IL and RL only account for the training of a single task. Even under multitask formulations of RL and IL , each new task considered requires a corresponding and sizable human effort. RL additionally faces significant optimization challenges in the multitask setting, often leading to worse data efficiency than learning tasks individually . This makes it difficult to scale either approach naively to the broad task setting of a generalist robot.
Task-agnostic control. This paper builds on the setting of task-agnostic control, where a single agent must be able to reach any reachable goal state in its environment upon command . One way of acquiring this kind of control is to first learn a model of the environment through interaction then use it for planning. However, these approaches face the same intractable autonomous exploration problem that RL does, requiring either environments simple enough to explore fully with random actions or hand-scripted primitives to guide richer behavior. A powerful model-free strategy for task-agnostic control is goal relabeling . This self-supervised technique trains goal conditioned policies to reach any previously visited state upon demand, with many recent examples in RL . However, when combined high dimensional observation spaces like images, relabeling results in policies that must be instructed with goal images at test time—a prohibitively expensive assumption in open world (non-simulator) environments. The present work builds heavily on relabeled imitation, but additionally equips policies with flexible natural language conditioning.
Covering state space.
Learning generally requires exposure to diverse training data. While relabeling allows for goal-directed learning from any experience, it cannot account for the diversity of that experience, which comes entirely from the underlying data. In task agnostic control, where agents must be prepared to reach any user-proposed goal state at test time, an effective data collection strategy is one that visits as many states as possible during training . Obtaining this sort of state space coverage autonomously is a long-standing problem motivating work on tractable heuristics , intrinsic motivation , and more recent information-theoretic approaches
. Success so far has been limited to restricted environments , as automatic exploration quickly becomes intractable in complex settings like object manipulation, where even knowing which states are valid presents a major challenge . Teleoperated play data sidesteps this exploration problem entirely, using prior human knowledge of object affordances to cover state space. This type of data stands in contrast to conventional teleoperated multitask demonstrations , whose diversity is necessarily constrained by an upfront task definition. Play data has served as the basis for relabeled IL and relabeled hierarchical RL . Play combined with relabeled IL is a central component of this work.
Multicontext learning. A number of previous methods have focused on generalizing across tasks , or generalizing across goals . We introduce multicontext learning, a framework for generalizing across heterogeneous task and goal descriptions, e.g. goal image and natural language. When one of the training sources is plentiful and the other scarce, multicontext learning can be seen as transfer learning through a shared goal space. Multicontext imitation is a central component of our method, as it reduces the cost of human language supervision to the point where it can be practically applied to learn open-ended instruction following.
Instruction following. There is a long history of research into agents that not only learn a grounded language understanding , but demonstrate that understanding by following instructions . Recently, authors have had success using deep learning to directly map raw input and text instructions to actions. However, prior work often studies restricted environments and simplified actuators . Additionally, learning to follow natural language is still not the standard in instruction-following research , with typical implementations instead assuming access to simulator-provided instructions drawn from a restricted vocabulary and grammar .
This work, in contrast, studies 1) natural language instructions, 2) high-dimensional continuous sensory inputs and actuators, and 3) complex tasks like long-horizon 3D robotic object manipulation. Furthermore, unlike existing RL approaches to instruction following, our IL method is highly sample efficient, requires no reward definition, and trivially scales to the multitask setting.
Transfer learning from generic text corpora. Transfer learning from large "in the wild" text corpora, e.g. Wikipedia, to downstream tasks is prevalent in NLP , but has been relatively unexplored for language-guided control. An identified reason for this gap is that tasks studied so far use small synthetic language corpora and are typically too artificial to benefit from transfer from real-world textual corpora. Like , we study instruction following in a simulated 3D home with real-world semantics, but expand the setting further to robotic object manipulation under realistic physics. This allows us to show the first example, to our knowledge, of positive transfer from "in the wild" text corpora to instruction following, making our agent better at language-guided manipulation and allowing it to follow many instructions outside its training set.
3. Preliminaries
We first review the prior settings of relabeled imitation learning and LfP, then introduce LangLfP, our natural language extension of LfP which builds on these components.
3.1 Relabeled imitation learning
Goal conditioned learning trains a single agent to reach any goal. This is formalized as a goal conditioned policy $\pi_{\theta}(a | s, g)$, which outputs next action $a \in A$, conditioned on current state $s \in S$ and a task descriptor $g \in G$. Imitation approaches learn this mapping using supervised learning over a dataset $\mathcal{D} = \{(\tau,g)_i\}^N_i$, of expert state-action trajectories $\tau = \{(s_0, a_0), ... \}$ solving for a paired task descriptor (typically a one-hot task encoding ).
A convenient choice for a task descriptor is some goal state $g = s_g \in S$ to reach. This allows any state visited during collection to be relabeled as a "reached goal state", with the preceding states and actions treated as optimal behavior for reaching that goal. Applied to some original dataset $\mathcal{D}$, this yields a much larger dataset of relabeled examples $\mathcal{D}_R = \{(\tau, s_g)_i\}^{N_{R}}_i$, $N_{R} >> N$, providing the inputs to a simple maximum likelihood objective for goal directed control: relabeled goal conditioned behavioral cloning (GCBC) :
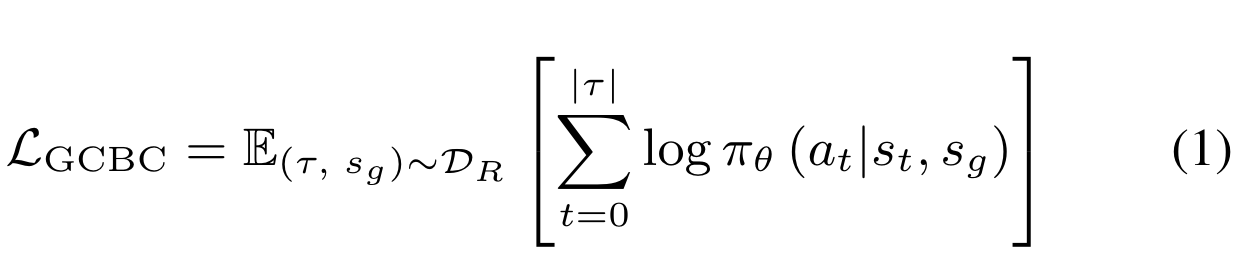
While relabeling automatically generates a large number of goal-directed demonstrations at training time, it cannot account for the diversity of those demonstrations, which comes entirely from the underlying data. To be able to reach any user-provided goal, this motivates data collection methods, upstream of relabeling, that fully cover state space.
3.2 Teleoperated play
Human teleoperated "play" collection directly addresses the state space coverage problem. In this setting, an operator is no longer constrained to a set of predefined tasks, but rather engages in every available object manipulation in a scene (example of play data). The motivation is to fully cover state space using prior human knowledge of object affordances. During collection, the stream of onboard robot observations and actions are recorded, $\{(s_t, a_t)\}^{\infty}_{t=0}$, yielding an unsegmented dataset of unstructured but semantically meaningful behaviors, useful in a relabeled imitation learning context.
3.3 Learning from play
LfP combines relabeled imitation learning with teleoperated play. First, unsegmented play logs are relabeled using Algorithm 2. This yields a training set $D_{\mathrm{play}} = \{(\tau, s_g)_i\}^{D_{\mathrm{play}}}_{i=0}$, holding many diverse, short-horizon examples. These can be fed to a standard maximum likelihood goal conditioned imitation objective:
4. Learning to Follow Human Language Instructions
A limitation of LfP—and other approaches that combine relabeling with image state spaces—is that behavior must be conditioned on a goal image $s_g$ at test time. In this work, we focus on a more flexible mode of conditioning: humans describing tasks in natural language. Succeeding at this requires solving a complicated grounding problem. To address this, we introduce Hindsight Instruction Pairing (Section 4.1), a method for pairing large amounts of diverse robot sensor data with relevant human language. To leverage both image goal and language goal datasets, we introduce multicontext imitation learning (Section 4.2). In (Section 4.3), we describe LangLfP which ties together these components to learn a single policy that follows many human instructions over a long horizon.
4.1 Pairing robot experience with human language
From a statistical machine learning perspective, an obvious candidate for grounding human language in robot sensor data is a large corpora of robot sensor data paired with relevant language. One way to collect this data is to choose an instruction, then collect optimal behavior. Instead we sample any robot behavior from play, then collect an optimal instruction. We call this Hindsight Instruction Pairing (Algorithm 3, part 1 of Figure 1). Just like how a hindsight goal image is an after-the-fact answer to the question "which goal state makes this trajectory optimal?", a hindsight instruction is an after-the-fact answer to the question "which language instruction makes this trajectory optimal?". We obtain these pairs by showing humans onboard robot sensor videos, then asking them "what instruction would you give the agent to get from first frame to last frame?" See examples in Video 3.
Video 3. Examples of our training data: We sample random experiences from teleoperated play, then ask humans: "what instruction would you give the agent to get from first frame to last frame?"
Concretely, our pairing process assumes access to $D_{\mathrm{play}}$, obtained using
Algorithm 2 and a pool of non-expert human overseers. From $D_{\mathrm{play}}$, we create a new dataset $D_{\mathrm{(play,lang)}} = \{(\tau, l)_i\}^{D_{\mathrm{(play,lang)}}}_{i=0}$, consisting of short-horizon play sequences $\tau$ paired with $l \in L$, a human-provided hindsight instruction with no restrictions on vocabulary or grammar.
This process is scalable because pairing happens after-the-fact, making it straightforward to parallelize via crowdsourcing. The language collected is also naturally rich, as it sits on top of play and is similarly not constrained by an upfront task definition. This results in instructions for functional behavior (e.g. "open the drawer", "press the green button"), as well as general non task-specific behavior (e.g. "move your hand slightly to the left." or "do nothing.") See more real examples in Table 5 and video examples of our paired training data here. Crucially, we do not need pair every experience from play with language to learn to follow instructions. This is made possible with multicontext imitation learning, described next.
 Algorithm 1: Multicontext Imitation Learning.
Algorithm 1: Multicontext Imitation Learning.
4.2 Multicontext imitation learning
So far, we have described a way to create two contextual imitation datasets: $D_{\mathrm{play}}$ holding hindsight goal image examples and $D_{\mathrm{(play,lang)}}$, holding hindsight instruction examples. Ideally, we could train a single policy that is agnostic to either task description. This would allow us to share statistical strength over multiple datasets during training, then free us to use just language specification at test time.
With this motivation, we introduce multicontext imitation learning (MCIL), a simple and universally applicable generalization of contextual imitation to multiple heterogeneous contexts. The main idea is to represent a large set of policies by a single, unified function approximator that generalises over states, tasks, and task descriptions. Concretely, MCIL assumes access to multiple imitation learning datasets $\mathcal{D} = \{D^0, ...,\ D^K\}$, each with a different way of describing tasks. Each $D^k = \{(\tau^{k}_i, c_{i}^k)\}^{D^k}_{i=0}$ holds pairs of state-action trajectories $\tau$ paired with some context $c \in C$. For example, $D^0$ might contain demonstrations paired with one-hot task ids (a conventional multitask imitation learning dataset), $D^1$ might contain image goal demonstrations, and $D^2$ might contain language goal demonstrations.
Rather than train one policy per dataset, MCIL instead trains a single latent goal conditioned policy $\pi_{\theta}(a_t | s_t, z)$ over all datasets simultaneously, learning to map each task description type to the same latent goal space $z \in \mathbb{R}^d$. See Figure 2. This latent space can be seen as a common abstract goal representation shared across many imitation learning problems. To make this possible, MCIL assumes a set of parameterized encoders $\mathcal{F} = \{f_{\theta}^0, ..., f_{\theta}^K\}$, one per dataset, each responsible for mapping task descriptions of a particular type to the common latent goal space, i.e. $z = f_{\theta}^k(c^k)$. For instance these could be a task id embedding lookup, an image encoder, and a language encoder respectively.
MCIL has a simple training procedure: At each training step, for each dataset $D^k$ in $\mathcal{D}$, sample a minibatch of trajectory-context pairs $(\tau^k, c^k) \thicksim D^k$, encode the contexts in latent goal space $z = f_{\theta}^k(c^k)$, then compute a simple maximum likelihood contextual imitation objective:
The full MCIL objective averages this per-dataset objective over all datasets at each training step,
and the policy and all goal encoders are trained end to end to maximize $\mathcal{L}_{\textrm{MCIL}}$. See Algorithm 1 for full minibatch training pseudocode.
Multicontext learning has properties that make it broadly useful beyond this paper. While we set $\mathcal{D} = \{D_{\mathrm{play}}, D_{\mathrm{(play,lang)}}\}$ in this paper, this approach allows more generally for training over any set of imitation datasets with different descriptions—e.g. task id, language, human video demonstration, speech, etc.
Being context-agnostic enables a highly efficient training scheme: learn the majority of control from the cheapest data source, while learning the most general form of task conditioning from a small number of labeled examples. In this way, multicontext learning can be interpreted as transfer learning through a shared goal space. We exploit this strategy in this work. Crucially, this can reduce the cost of human oversight to the point where it can be practically applied. Multicontext learning allows us to train an agent to follow human instructions with less than 1% of collected robot experience requiring paired language, with the majority of control learned instead from relabeled goal image data.
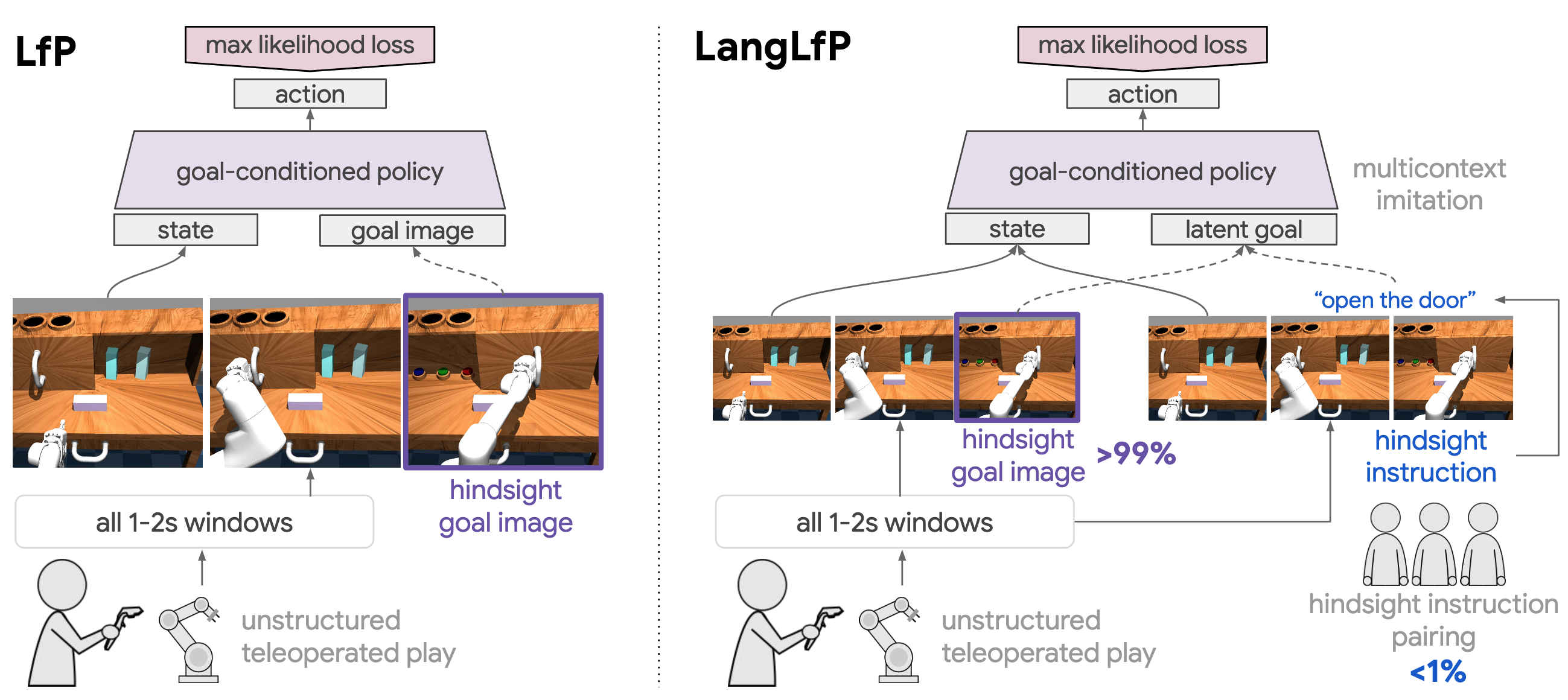 Figure 3: Comparing original goal image conditioned LfP (left) to goal image or natural language conditioned LangLfP (right): Both are trained on top of teleoperated play, relabeled into millions of goal image conditioned imitation examples. LangLfP is additionally trained on play windows paired with hindsight instructions. This multicontext training allows for the majority of control to be learned from self-supervision (>99% relabeled play), with <1% of play windows requiring language pairing.
Figure 3: Comparing original goal image conditioned LfP (left) to goal image or natural language conditioned LangLfP (right): Both are trained on top of teleoperated play, relabeled into millions of goal image conditioned imitation examples. LangLfP is additionally trained on play windows paired with hindsight instructions. This multicontext training allows for the majority of control to be learned from self-supervision (>99% relabeled play), with <1% of play windows requiring language pairing.
4.3 LangLfP: following image and language goals.
We now have all the components to introduce LangLfP (language conditioned learning from play). LangLfP is a special case of multicontext imitation learning (Section 4.2) applied to our problem setting.
At a high level, LangLfP trains a single multicontext policy $\pi_\theta(a_t | s_t, z)$ over datasets $\mathcal{D} = \{\DPLAY, \DPLAYLANG\}$, consisting of hindsight goal image tasks and hindsight instruction tasks. We define $\mathcal{F} = \{g_{\textrm{enc}}, s_{\textrm{enc}}\}$, neural network encoders mapping from image goals and instructions respectively to the same latent visuo-lingual goal space. LangLfP learns perception, natural language understanding, and control end-to-end with no auxiliary losses. We discuss the separate modules below.
Perception module. In our experiments, $\tau$ in each example consists of $\{(O_t, a_t)\}_t^{|\tau|}$, a sequence of onboard observations $O_t$ and actions. Each observation contains a high-dimensional image and internal proprioceptive sensor reading. A learned perception module $P_{\theta}$ maps each observation tuple to a low-dimensional embedding, e.g. $s_t = P_{\theta}(O_t)$, fed to the rest of the network. See Appendix B.1 for details on our perception architecture. This perception module is shared with $g_{\textrm{enc}}$, which defines an additional network on top to map encoded goal observation $s_g$ to a point in $z$ space. See Appendix B.2 for details.
Language module.
Our language goal encoder $s_{\textrm{enc}}$ tokenizes raw text $l$ into subwords , retrieves subword embeddings from a lookup table, then summarizes embeddings into a point in $z$ space. Subword embeddings are randomly initialized at the beginning of training and learned end-to-end by the final imitation loss. See Appendix B.3 for $s_{\textrm{enc}}$ implementation details.
Control module.
While we could in principle use any architecture to implement the multicontext policy $\pi_\theta(a_t | s_t, z)$, we use Latent Motor Plans (LMP) . LMP is a goal-directed imitation architecture that uses latent variables to model the large amount of multimodality inherent to freeform imitation datasets. Concretely, it is a sequence-to-sequence conditional variational autoencoder (seq2seq CVAE) autoencoding contextual demonstrations through a latent "plan" space. The decoder is a goal conditioned policy. As a CVAE, LMP lower bounds maximum likelihood contextual imitation (Equation 1), and is easily adapted to our multicontext setting. See Appendix B.4 for details on this module.
LangLfP training.
Figure 3 compares LangLfP training to original LfP training. At each training step we sample a batch of image goal tasks from $D_{\mathrm{play}}$ and a batch of language goal tasks from $D_{\mathrm{(play,lang)}}$. Observations are encoded into state space using the perception module $P_{\theta}$. Image and language goals are encoded into latent goal space $z$ using encoders $g_{\textrm{enc}}$ and $s_{\textrm{enc}}$. We then use $\pi_\theta(a_t | s_t, z)$ to compute the multicontext imitation objective, averaged over both task descriptions. We take a combined gradient step with respect to all modules—perception, language, and control—optimizing the whole architecture end-to-end as a single neural network. See a details in Appendix B.5.
Following human instructions at test time.
At the beginning of a test episode the agent receives as input its onboard observation $O_t$ and a human-specified natural language goal $l$. The agent encodes $l$ in latent goal space $z$ using the trained sentence encoder $s_{\textrm{enc}}$. The agent then solves for the goal in closed loop, repeatedly feeding the current observation and goal to the learned policy $\pi_{\theta}(a|s_t, z)$, sampling actions, and executing them in the environment. The human operator can type a new language goal $l$ at any time. See picture in part 3 of Figure 1.
4.4 Transferring knowledge from generic text corpora
Large "in the wild" natural language corpora reflect substantial human knowledge about the world . Many recent works have successfully transferred this knowledge to downstream tasks in NLP via pretrained embeddings . Can we achieve similar knowledge transfer to robotic manipulation?
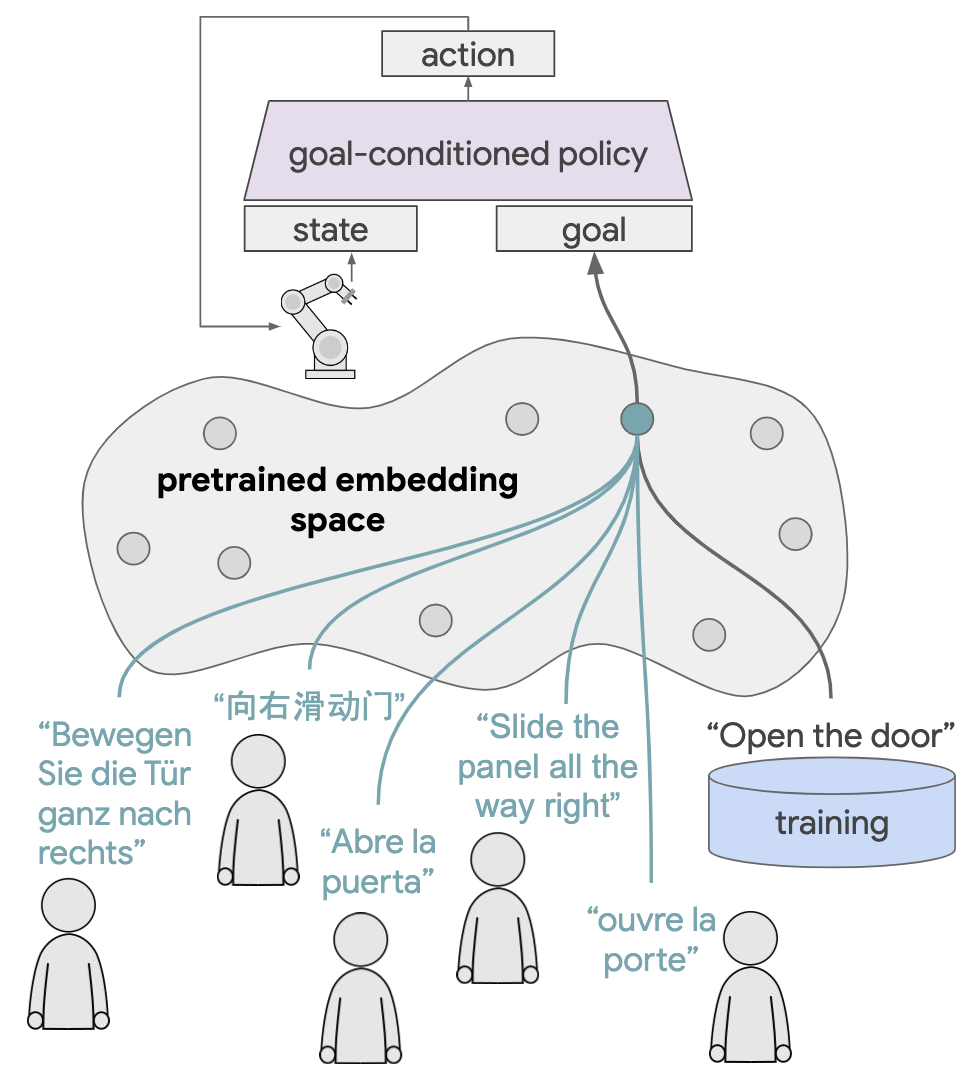 Figure 4. Following novel instructions at test time in zero shot using transfer learning: Simply by training on top of pretrained language embeddings, we can give a language conditioned policy the ability to follow out of distribution instructions in zero shot at test time. The pretrained embedding space is responsible for relating novel instructions (green) to ones the agent has been trained to follow (black).
Figure 4. Following novel instructions at test time in zero shot using transfer learning: Simply by training on top of pretrained language embeddings, we can give a language conditioned policy the ability to follow out of distribution instructions in zero shot at test time. The pretrained embedding space is responsible for relating novel instructions (green) to ones the agent has been trained to follow (black).
We hypothesize two benefits to this type of transfer. First, if there is a semantic match between the source corpora and the target environment, more structured inputs may act as a strong prior, shaping grounding or control . Second, language embeddings have been shown to encode similarity between large numbers of words and sentences. This may allow an agent to follow many novel instructions in zero shot, provided they are sufficiently "close" to ones it has been trained to follow (Figure 4).
Note, given the complexity of natural language, it is likely that robots in open-world environments will need to be able to follow synonym commands outside of a particular training set.
To test these hypotheses, we introduce a simple transfer learning technique, generally applicable to any natural language conditioned agent. We assume access to a neural language model, pretrained on large unlabeled text corpora, capable of mapping full sentences $l$ to points in a semantic vector space $v \in \mathbb{R}^d$. Transfer is enabled simply by encoding language inputs $l$ to the policy at training and test time in $v$ before feeding to the rest of the network. We augment LangLfP in this way, which we refer to as TransferLangLfP. See AppendixAppendix B.3 for details.
5. Experimental Setup
Our experiments aim to answer the following questions:
- "Ask me anything" scenario: Can LangLfP train a single agent to solve many human language conditioned robotic manipulation tasks in a row? How does LangLfP compare to prior goal image conditioned LfP, which has less practical task specification? How does our model, trained on unlabeled play, compare to an identical architecture trained on conventional labeled multitask demonstrations?
- Transfer from unlabeled text corpora: Can knowledge be transferred from text to downstream robotic manipulation? Does our transfer learning technique allow a policy to follow novel instructions in zero shot?
 Figure 5. Playroom environment: A situated robot in a 3D Mujoco environment.
Figure 5. Playroom environment: A situated robot in a 3D Mujoco environment.
5.1 3D simulated environment
We conduct our experiments in the simulated 3D Playroom environment introduced in , shown in Figure 5. The environment contains a desk with a sliding door and drawer that can be opened and closed. On the desk is a movable rectangular block and 3 buttons that can be pushed to control different colored lights. Next to the desk is a trash bin. Physics are simulated using the MuJoCo physics engine . Videos here of play data collected in this environment give a good idea of the available complexity. In front of the desk is a realistic simulated 8-DOF robot (arm and parallel gripper). The agent perceives its surroundings from egocentric high-dimensional RGB video sensors. It additionally has access to continuous internal proprioceptive sensors, relaying the cartesian position and rotation of its end effector and gripper angles. We modify the environment to include a text channel which the agent observes at each timestep, allowing humans to type unconstrained language commands. The agent must perform high-frequency, closed-loop continuous control to solve for user-described manipulation tasks, sending continuous position, rotation, and gripper commands to its arm at 30hz. See Appendix C for details.
5.2 Methods
In our experiments, we compare the following methods (more details in Appendix E):
-
LangBC ("language, but no play"): a baseline natural language conditioned multitask imitation policy , trained on $D_{\mathrm{(play,lang)}}$, 100 expert demonstrations for each of the 18 evaluation tasks paired with hindsight instructions.
-
LfP ("play, but no language"): a baseline LfP model trained on $D_{\mathrm{play}}$, conditioned on goal images at test time.
-
LangLfP (ours) ("play and language"): Multicontext imitation trained on $D_{\mathrm{play}}$ and play paired with language $D_{\mathrm{(play,lang)}}$. Tasks are specified at test time using only natural language.
-
Restricted LangLfP To make a controlled comparison to LangBC, we train a baseline of LangLfP on "restricted $D_{\mathrm{play}}$", a play dataset restricted to be the same size as $D_{\mathrm{(play,lang)}}$. This restriction is artificial, as more unsegmented play can be collected with the same budget of time. This helps answer "for the same exact amount of data, which kind of data leads to better generalization: conventional multitask demonstrations, or relabeled play?".
-
TransferLangLfP (ours): transfer learning augmented LangLfP, identical except instruction inputs are replaced with pretrained language embeddings.
We define two sets of experiments for each baseline: pixel experiments, where models receive high-dimensional image observations and must learn perception end-to-end, and state experiments, where models instead receive the ground truth simulator state consisting of positions and orientations for all objects in the scene. The latter provides an upper bound on how all well the various methods can learn language conditioned control, independent of a difficult perception problem (which may be improved upon independently with self-supervised representation learning methods (e.g. ).
Note that all baselines can be seen as maximizing the same multicontext imitation objective, differing only on the particular composition of data sources. Therefore, to perform a controlled comparison, we use the same imitation architecture (details in Appendix B) across all baselines. See Appendix D for a detailed description of all data sources.
6. "Ask Me Anything" Experiments
While one-off multitask evaluations are challenging and interesting, a realistic and significantly more difficult scenario is one in which a human gives a robot multiple instructions in a row over a long horizon, for example: "get the block from the shelf...now open the drawer...now sweep the block into the drawer...now close the drawer". Furthermore, agents should be able to accomplish any subtask in any order. This demands a training process that adequately covers transitions between arbitrary pairs of tasks. This setting of long-horizon human language conditioned robotic manipulation has not yet been explored in the literature to our knowledge. While difficult, we believe it aligns well with test-time expectations for a learning robot in everyday environments.
6.1 Long-Horizon Evaluation
We define a long horizon evaluation by significantly expanding upon the previous 18-task evaluation in , Multi-18. We construct many multi-stage evaluations by treating the original 18 tasks as subtasks, then consider all valid N-stage transitions between them. This results in 2-stage, 3-stage, and 4-stage long horizon manipulation benchmarks, referred to here as Chain-2, Chain-3, and Chain-4. Note that the number of unique tasks increases rapidly with N: there are 63 Chain-2 tasks, 254 Chain-3 tasks, and 925 Chain-4 tasks. Also note this multi-stage scenario subsumes the original Multi-18, which can be seen as just testing the first stage. This allows for direct comparison to prior work. See Appendix F for details on benchmark construction and evaluation walkthrough. We evaluate all methods on these long-horizon benchmarks and present the results in Table 1 and Figure 6, discussing our findings below. Success is reported with confidence intervals over 3 seeded training runs.
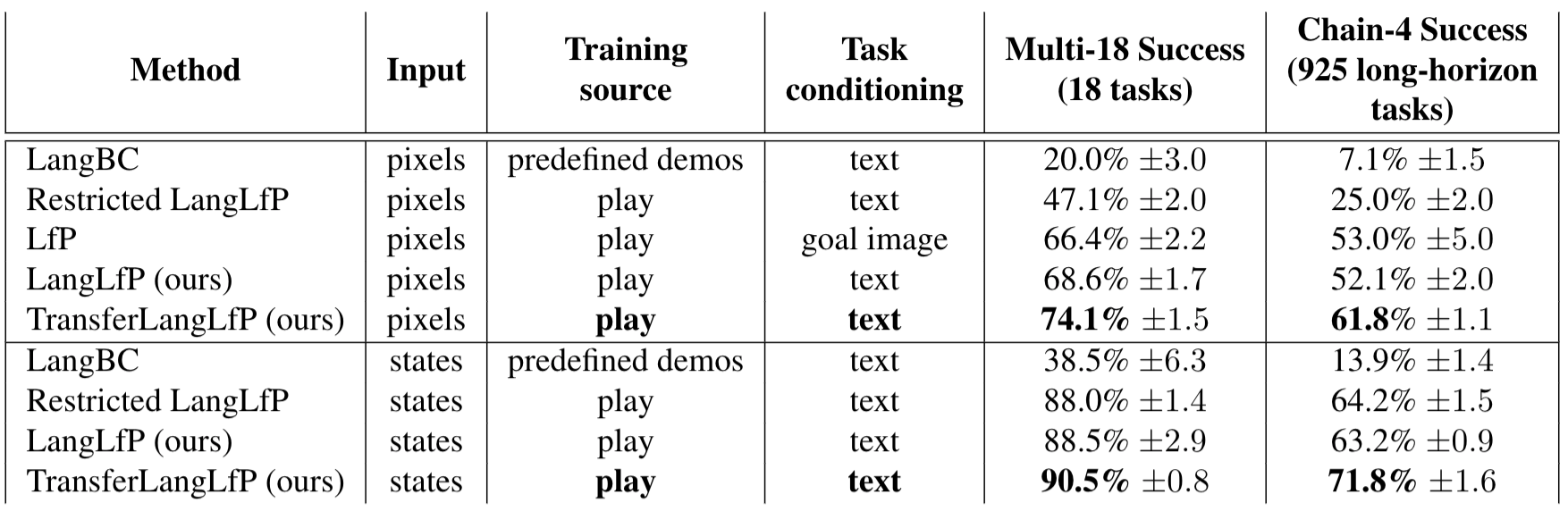 Table 1. "Ask Me Anything" experiments: long horizon, natural language conditioned visual manipulation with a human in the loop. We report the percentage of subtasks completed for one-off instructions (Multi-18) and four instructions in a row (Chain-4). We see that LangLfP matches the performance of LfP, but has a more scalable form of task conditioning. Additionally we see TransferLangLfP significantly benefits from knowledge transfer from generic text corpora, outperforming LangLfP and original LfP. Finally, models trained on unstructured play significantly outperform LangBC, trained on predefined task demonstrations, especially in the long horizon.
Table 1. "Ask Me Anything" experiments: long horizon, natural language conditioned visual manipulation with a human in the loop. We report the percentage of subtasks completed for one-off instructions (Multi-18) and four instructions in a row (Chain-4). We see that LangLfP matches the performance of LfP, but has a more scalable form of task conditioning. Additionally we see TransferLangLfP significantly benefits from knowledge transfer from generic text corpora, outperforming LangLfP and original LfP. Finally, models trained on unstructured play significantly outperform LangBC, trained on predefined task demonstrations, especially in the long horizon.
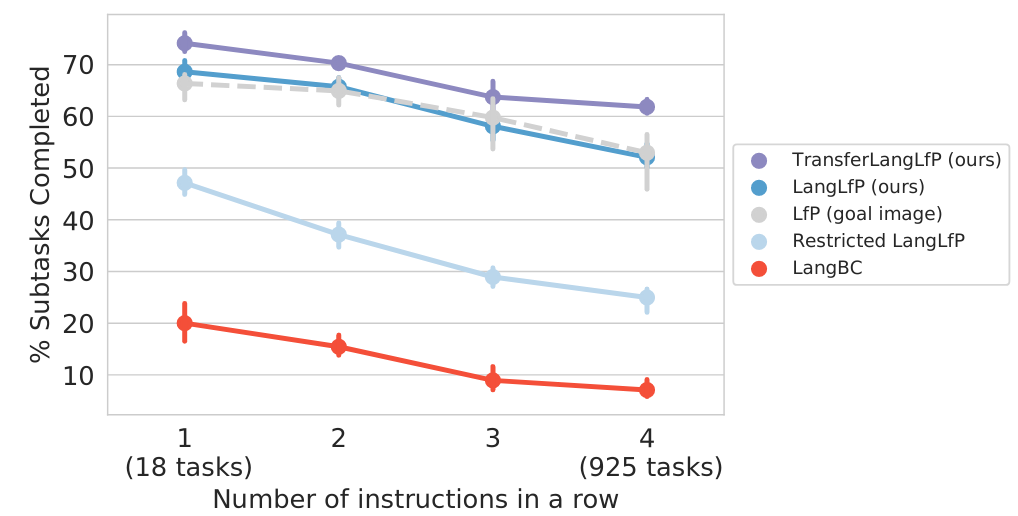 Figure 6. Multitask human language conditioned visual manipulation over a long horizon. Here we plot the performance of all methods as a human gives a sequence of natural language instructions to follow. Note there are 18 single instruction tasks, rising to 925 unique four instruction tasks. The x-axis considers the number of instructions given in a row and the y-axis considers the percentage of instructions successfully completed. We also plot goal image conditioned LfP performance for comparison.
Figure 6. Multitask human language conditioned visual manipulation over a long horizon. Here we plot the performance of all methods as a human gives a sequence of natural language instructions to follow. Note there are 18 single instruction tasks, rising to 925 unique four instruction tasks. The x-axis considers the number of instructions given in a row and the y-axis considers the percentage of instructions successfully completed. We also plot goal image conditioned LfP performance for comparison.
Video 4: Test time human language conditioned visual control. Here are examples of LangLfP following human instructions at test time from onboard observations. See more qualitative examples in Appendix G.
6.2 Long Horizon Results
Goal image conditioned comparison.
In Table 1, we find that LangLfP matches the performance of LfP on all benchmarks within margin of error, but does so with entirely from natural language task specification. Notably, this is achieved with only $\thicksim$0.1% of play requiring language pairing, with the majority of control still learned from self-supervised imitation. This is important because it shows our simple framework allows open-ended robotic manipulation to be combined with open-ended text conditioning with minimal additional human supervision. This was the main question of this work. We attribute these results to our multicontext learning setup, which allows statistical strength to be shared over multiple datasets, some plentiful and some scarce. See Video 4 for examples of a single LangLfP agent following many natural language instructions from onboard observations.
Conventional multitask imitation comparison.
We see in Table 1 and Figure 6 that LangLfP outperforms LangBC on every benchmark. Notably, this result holds even when the play dataset is artificially restricted to the same size as the conventional demonstration dataset (Restricted LangLfP vs LangBC). This is important because it shows that models trained on top of relabeled play generalize much better than those trained on narrow predefined task demonstrations, especially in the most difficult long horizon setting.
Qualitatively (Video 5), the difference between the training sources is striking. We find that play-trained policies can of transition well between tasks and recover from initial failures, while narrow demo-trained policies quickly encounter compounding imitation error and never recover. We believe this highlights the importance of training data that covers state space, including large numbers of tasks as well as non task-specific behavior like transitions.
Video 5: Play vs. conventional demonstrations. Here we qualitatively compare LangLfP to LangBC by providing each with the exact same set of 4 instructions.
| LangLfP |
LangBC |
|
|
|
Instructions:
1) "pull the drawer handle all the way"
2) "put the block in to the drawer"
3) "push the drawer in"
4) "move the door all the way right"
|
| LangLfP |
LangBC |
|
|
|
Instructions:
1) "drag the block out"
2) "push the door to the right"
3) "press blue"
4) "move the door all the way left"
|
| LangLfP |
LangBC |
|
|
|
Instructions:
1) "knock the object"
2) "pull the drawer handle all the way"
3) "drag the object into the drawer"
4) "close the drawer"
|
Following 15 instructions in a row. We present qualitative results in Video 6 showing that our agent can follow 15 natural language instructions in a row provided by a human. We believe success in this difficult scenario offers encouragement that simple high capacity imitation learning can be competitive with more complicated long horizon reinforcement learning methods.
Video 6. LangLfP follows 15 instructions in a row.
Play scales with model capacity.
In Figure 7, we consider task performance as a function of model size for models trained on play or conventional predefined demonstrations. For fair comparison, we compare
LangBC to Restricted LangLfP, trained on the same amount of data. We study both models from state inputs to understand upper bound performance. As we see, performance steadily improves as model size is increased for models trained on play, but peaks and then declines for models trained on conventional demonstrations. Our interpretation is that larger capacity is effectively utilized to absorb the diversity in play, whereas additional capacity is wasted on equivalently sized datasets constrained to predefined behaviors. This suggests that the simple recipe of collecting large play datasets and scaling up model capacity to achieve higher performance is a valid one.
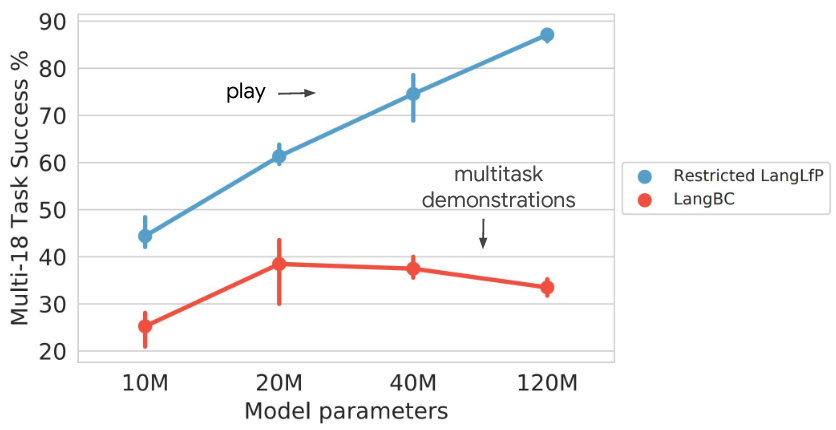 Figure 7. Play scales with model capacity. Large model capacity is well utilized to absorb diversity in unstructured play, but is wasted on an equivalent amount of conventional predefined task demonstrations.
Figure 7. Play scales with model capacity. Large model capacity is well utilized to absorb diversity in unstructured play, but is wasted on an equivalent amount of conventional predefined task demonstrations.
Language unlocks human assistance.
Natural language conditioned control allows for new modes of interactive test time behavior, allowing humans to give guidance to agents at test time that would be impractical to give via goal image or task id conditioned control. See Video 7 for a concrete example. During the long horizon evaluation, the arm of a LangLfP agent becomes stuck on top of the desk shelf. The operator is able to quickly specify a new subtask "pull your arm back", which the agent completes, leaving it in a much better initialization to complete the original task. This rapid interactive guidance would have required having a corresponding goal image on hand for "pull your arm back" in the image conditioned scenario or would have required learning an entire separate task using demonstrations in the task id conditioned scenario.
Video 7: Interactive human language assistance: The operator offers real time language guidance to the robot whose end-effector gets stuck, allowing it to solve for "press the red button".
Video 8: Composing new tasks with language.
In this section, we show that the operator can compose difficult new tasks on the fly with language, e.g. "put the object in the trash" or "put the object on top of the shelf". These tasks are outside the standard 18-task benchmark. LangLfP solves them in zero shot. Note that the operator helps the robot by breaking down the task into subtasks.
|
Putting the object in the trash: An operator is able to put the object in the trash by breaking down the task into 2 smaller subtasks with the following sentences; 1) "pick up the object" 2) "put the object in the trash".
|
Putting the object on top of the shelf: An operator is able to put the object in the trash by breaking down the task into 2 smaller subtasks with the following sentences; 1) "pick up the object" 2) "put the object on top of the shelf".
|
7. Knowledge Transfer Experiments
Here we evaluate our transfer learning augmentation to LangLfP. In these experiments, we are interested in two questions: 1) Is knowledge transfer possible from generic text corpora to language-guided robotic manipulation? 2) Does training on top of pretrained embeddings allow our policy to follow instructions it has never been trained on?
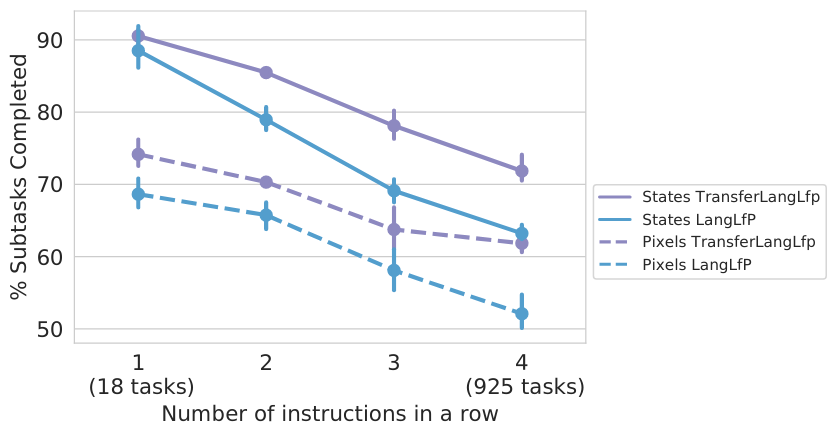 Figure 8. Knowledge transfer from generic text corpora to robotic manipulation.
TransferLangLfP, which trains on top of pretrained language embeddings, systematically outperforms LangLfP, which learns language understanding from scratch, on all manipulation benchmarks.
Figure 8. Knowledge transfer from generic text corpora to robotic manipulation.
TransferLangLfP, which trains on top of pretrained language embeddings, systematically outperforms LangLfP, which learns language understanding from scratch, on all manipulation benchmarks.
 Table 2. Following out of distribution instructions: Training on top of pretrained neural embeddings (TransferLangLfP) allows our agent to follow thousands of out-of-distribution synonym instructions in 16 languages in zero shot.
Table 2. Following out of distribution instructions: Training on top of pretrained neural embeddings (TransferLangLfP) allows our agent to follow thousands of out-of-distribution synonym instructions in 16 languages in zero shot.
7.1 Knowledge Transfer Results
Positive transfer to robotic manipulation.
In Table 1 and Figure 8, we see that while LangLfP and prior LfP perform comparably, TransferLangLfP systematically outperforms both. This is important because it shows the first evidence, to our knowledge, that world knowledge reflected in large unstructured bodies of text can be transferred downstream to improve language-guided robotic manipulation. As mentioned in , we hypothesize this transfer is possible because we conduct experiments in a 3D environment with realistic object interactions, matching the semantics of those described in real world textual corpora.
Following out of distribution "synonym instructions". To study whether our proposed transfer augmentation allows an agent to follow out-of-distribution instructions, we replace one or more words in each Multi-18 instruction with a synonym outside training, e.g. "drag the block from the shelf" $\xrightarrow{}$ "retrieve the brick from the cupboard". Enumerating all substitutions results in a set of 14,609 out-of-distribution instructions covering all 18 tasks. We evaluate a random policy, LangLfP, and TransferLangLfP on this benchmark, OOD-syn, reporting the results in Table 2. Success is reported with confidence intervals over 3 seeded training runs. We see while LangLfP is able to solve some novel tasks by inferring meaning from context (e.g. "pick up the block" and "pick up the brick" might reasonably map to the same task), its performance degrades significantly. TransferLangLfP on the other hand, generalizes substantially better. This shows that the simple transfer learning technique we propose greatly magnifies the test time scope of an instruction following agent, allowing it to follow thousands more user instructions than it was trained with. Given the inherent complexity of language, this is an important real world consideration.
Following out of distribution instructions in 16 different languages. Here we study a rather extreme case of out-of-distribution generalization: following instructions in languages not seen during training (e.g. French, Mandarin, German, etc.).
To study this, we combine the original set of test instructions from Multi-18 with the expanded synonym instruction set OOD-syn, then translate both into 16 languages using the Google translate API. This results in $\thicksim$240k out-of-distribution instructions covering all 18 tasks. We evaluate the previous methods on this cross-lingual manipulation benchmark, OOD-16-lang, reporting success in Table 2. We see that when LangLfP receives instructions with no training overlap, it resorts to producing maximum likelihood play actions. This results in some spurious task success, but performance degrades materially. Remarkably, TransferLangLfP solves a substantial portion of these in zero shot, degrading only slightly from the english-only benchmark. See Video 9, showing TransferLangLfP following instructions in 16 novel languages. These results show that simply training high capacity imitation policies on top of pretrained embedding spaces affords agents powerful zero shot generalization capabilities. While practically, one could imagine simply translating these instructions first into English before feeding them to our system, this demonstrates that a large portion of the necessary analogical reasoning can happen internal to the agent in a manner that is end-to-end differentiable. While in this paper we do not finetune the embeddings in this manner, an exciting direction for future work would be to see if grounding language embeddings in embodied imitation improves representation learning over text-only inputs.
Video 9: Transfer unlocks zero shot instruction following
Following instructions in 16 different languages
Real-time instructions in French, even though agent only trained with English. 6 instructions: "open the drawer... put the object into the drawer...take the object out of the drawer...close the drawer...grasp the object...put the object in the bin."
8. Limitations and Future Work
Although the coverage of play mitigates failure modes in conventional imitation setups, we observe several limitations in our policies at test time.
In this video, we see the policy make multiple attempts to solve the task, but times out before it is able to do so. We see in this video that the agent encounters a particular kind of compounding error, where the arm flips into an awkward configuration, likely avoided by humans during teleoperated play. This is potentially mitigated by a more stable choice of rotation representation, or more varied play collection. We note that the human is free to help the agent out of these awkward configurations using language assistance, as shown in Video 7. More examples of failures can be seen here.
Failure: The agent times out attempting to lift the block.
Failure: The agent encounters an arm configuration likely avoided by human operators during teleoperated play, leading to compounding error.
While LangLfP relaxes important constraints around task specification, it is fundamentally a goal-directed imitation method and lacks a mechanism for autonomous policy improvement. An exciting area for future work may be one that combines the coverage of teleoperated play, the scalability and flexibility of multicontext imitation pretraining, and the autonomous improvement of reinforcement learning, similar to prior successful combinations of LfP and RL .
As in original LfP, the scope of this work is task-agnostic control in a single environment. We note this is consistent with the standard imitation assumptions that training and test tasks are drawn i.i.d. from the same distribution. An interesting question for future work is whether training on a large play corpora covering many rooms and objects allows for generalization to unseen rooms or objects.
Simple maximum likelihood makes it easy to learn large capacity perception and control architectures end-to-end. It additionally enjoys significant sample efficiency and stability benefits over multitask RL at the moment . We believe these properties provide good motivation for continuing to scale larger end-to-end imitation architectures over larger play datasets as a practical strategy for task-agnostic control.
9. Conclusion
Robots that can learn to relate human language to their perception and actions would be especially useful in open-world environments.
This work asks: provided real humans play a direct role in this learning process, what is the most efficient way to go about it?
With this motivation, we introduced LangLfP, an extension of LfP trained both on relabeled goal image play and play paired with human language instructions. To reduce the cost of language pairing, we introduced Multicontext Imitation Learning, which allows a single policy to be trained over both goal image and language tasks, then use just language conditioning at test time.
Crucially, this made it so that less than 1% collected robot experience required language pairing to enable the new mode of conditioning. In experiments, we found that a single policy trained with LangLfP can solve many 3D robotic manipulation tasks over a long horizon, from onboard sensors, and specified only via human language. This represents a considerably more complex scenario than prior work in instruction following. Finally, we introduced a simple technique allowing for knowledge transfer from large unlabeled text corpora to robotic manipulation. We found that this significantly improved downstream visual control—the first instance to our knowledge of this kind of transfer. It also equipped our agent with the ability to follow thousands of instructions outside its training set in zero shot, in 16 different languages.
Appendix
A. Relabeling play
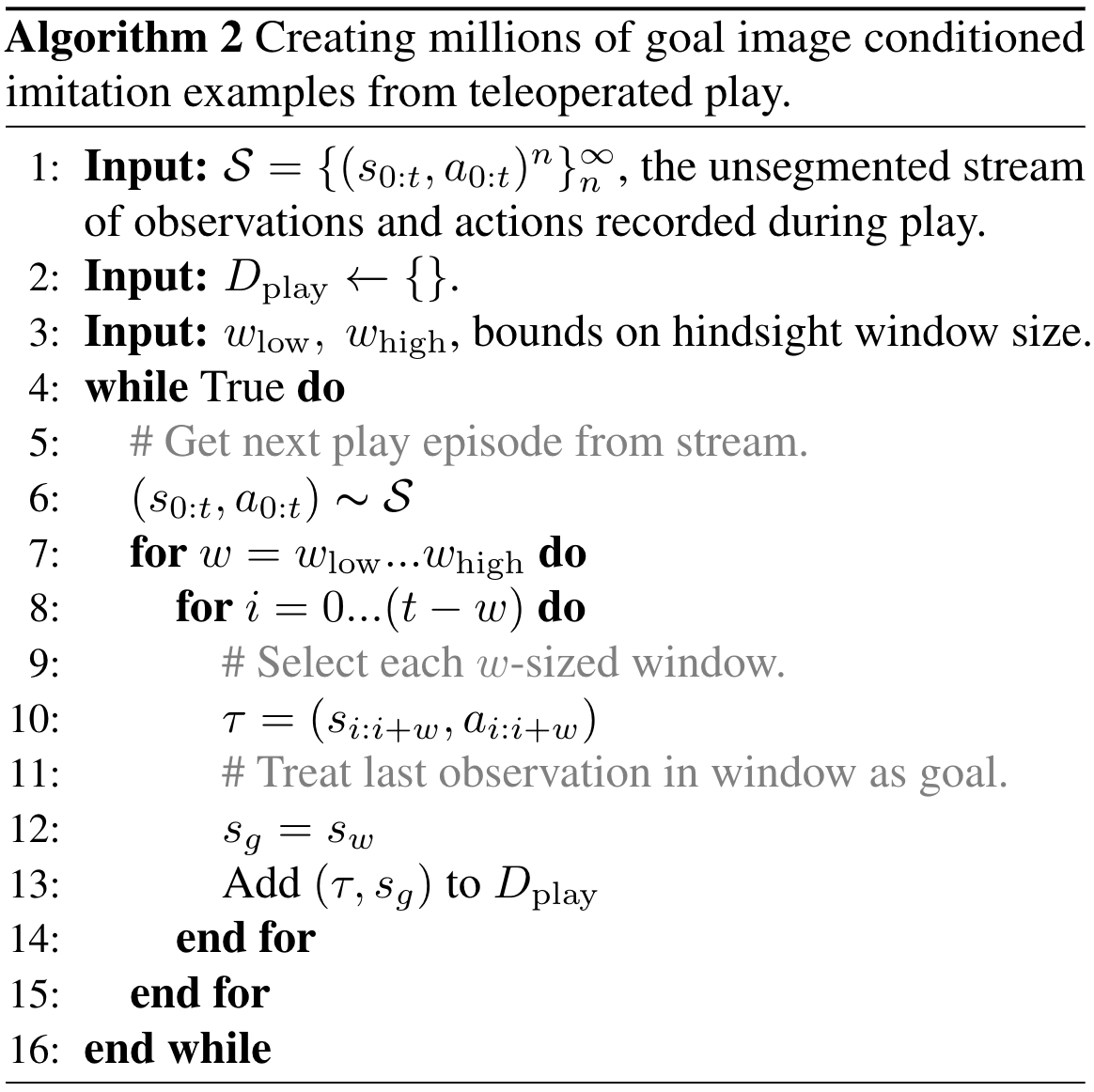 Algorithm 2: Relabeling play into many goal image demonstrations.
Algorithm 2: Relabeling play into many goal image demonstrations.
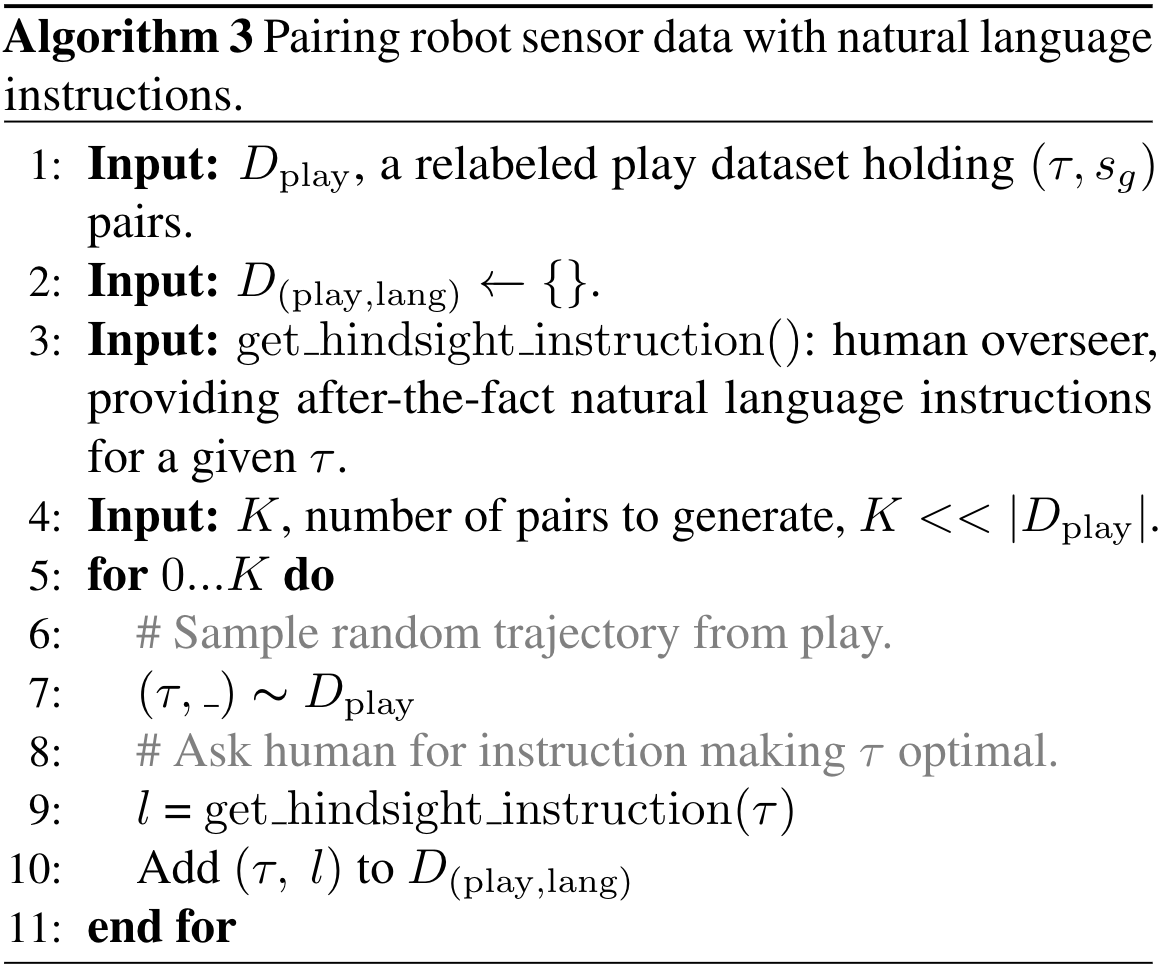 Algorithm 3: Scalably pairing robot experience with relevant human language.
Algorithm 3: Scalably pairing robot experience with relevant human language.
B. LangLfP Implementation Details
Below we describe the networks we use for perception, natural language understanding, and control—all trained end-to-end as a single neural network to maximize our multicontext imitation objective. We stress that this is only one implementation of possibly many for LangLfP, which is a general high-level framework 1) combining relabeled play, 2) play paired with language, and 3) multicontext imitation.
B.1 Perception Module
We map raw observations (image and proprioception) to low dimensional perceptual embeddings that are fed to the rest of the network. To do this we use the perception module described in Figure 9. We pass the image through the network described in Table 3, obtaining a 64-dimensional visual embedding. We then concatenate this with the proprioception observation (normalized to zero mean, unit variance using training statistics). This results in a combined perceptual embedding of size 72.
This perception module is trained end to end to maximize the final imitation loss. We do no photometric augmentation on the image inputs, but anticipate this may lead to better performance.
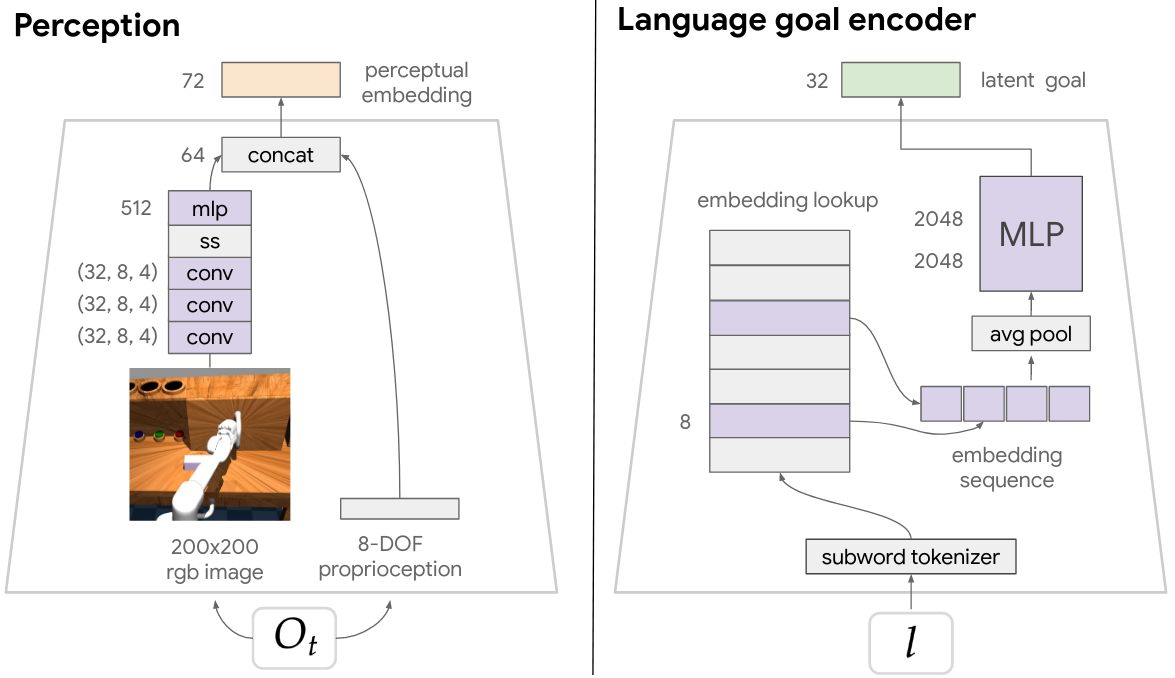 Figure 9. Perception and language embedder modules.
Figure 9. Perception and language embedder modules.
 Table 3. Hyperparameters for vision network.
Table 3. Hyperparameters for vision network.
B.2 Image goal encoder
$g_{\textrm{enc}}$ takes as input image goal observation $O_g$ and outputs latent goal $z$. To implement this, we reuse the perception module $P_{\theta}$, described in Appendix B.1, which maps $O_g$ to $s_g$. We then pass $s_g$ through a 2 layer 2048 unit ReLU MLP to obtain $z$.
B.3 Language understanding module
From scratch. For LangLfP, our latent language goal encoder, $s_{\textrm{enc}}$, is described in Figure 9. It maps raw text to a 32 dimensional embedding in goal space as follows: 1) apply subword tokenization, 2) retrieve learned 8-dim subword embeddings from a lookup table, 3) summarize the sequence of subword embeddings (we considered average pooling and RNN mechanisms for this, choosing average pooling based on validation), and 4) pass the summary through a 2 layer 2048 unit ReLU MLP. Out-of-distribution subwords are initialized as random embeddings at test time.
Transfer learning.
For our experiments, we chose Multilingual Universal Sentence Encoder described in . MUSE is a multitask language architecture trained generic multilingual corpora (e.g. Wikipedia, mined question-answer pair datasets), and has a vocabulary of 200,000 subwords. MUSE maps sentences of any length to a 512-dim vector. We simply treat these embeddings as language observations and do not finetune the weights of the model. This vector is fed to a 2 layer 2048 unit ReLU MLP, projecting to latent goal space.
We note there are many choices available for encoding raw text in a semantic pretrained vector space. MUSE showed results immediately and we moved onto different decisions. We look forward to experimenting with different choices of pretrained embedder in the future.
B.4 Control Module
Multicontext LMP. Here we describe "multicontext LMP": LMP adapted to be able to take either image or language goals. This imitation architecture learns both an abstract visuo-lingual goal space $z^g$, as well as a plan space $z^p$ capturing the many ways to reach a particular goal. We describe this implementation now in detail.
As a conditional seq2seq VAE, original LMP trains 3 networks. 1) A posterior $q(z^p|\tau)$, mapping from full state-action demonstration $\tau$ to a distribution over recognized plans. 2) A learned prior $p(z^p|s_0, s_g)$, mapping from initial state in the demonstration and goal to a distribution over possible plans for reaching the goal. 3) A goal and plan conditioned policy $p(a_t|s_t, s_g, z^p)$, decoding the recognized plan with teacher forcing to reconstruct actions that reach the goal.
To train multicontext LMP, we simply replace the goal conditioning on $s_g$ everywhere with conditioning on $z^g$, the latent goal output by multicontext encoders $\mathcal{F}= \{g_{\textrm{enc}},s_{\textrm{enc}}\}$. In our experiments, $g_{\textrm{enc}}$ is a 2 layer 2048 unit ReLU MLP, mapping from encoded goal image $s_g$ to a 32 dimensional latent goal embedding. $s_{\textrm{enc}}$ is a subword embedding summarizer described in Appendix B.3. Unless specified otherwise, the LMP implementation in this paper uses the same hyperparameters and network architecture as in . See appendix there for details on the posterior, conditional prior, and decoder architecture, consisting of a RNN, MLP, and RNN respectively.
B.5 Training Details
At each training step, we compute two contextual imitation losses: image goal and language goal. The image goal forward pass is described in Figure 16. The language goal forward pass is described in Figure 17. We share the perception network and LMP networks (posterior, prior, and policy) across both steps. We average minibatch gradients from image goal and language goal passes and we train everything—perception networks, $g_{\textrm{enc}}$, $s_{\textrm{enc}}$, posterior, prior, and policy—end-to-end as a single neural network to maximize the combined training objective. We describe all training hyperparameters in Table 4.
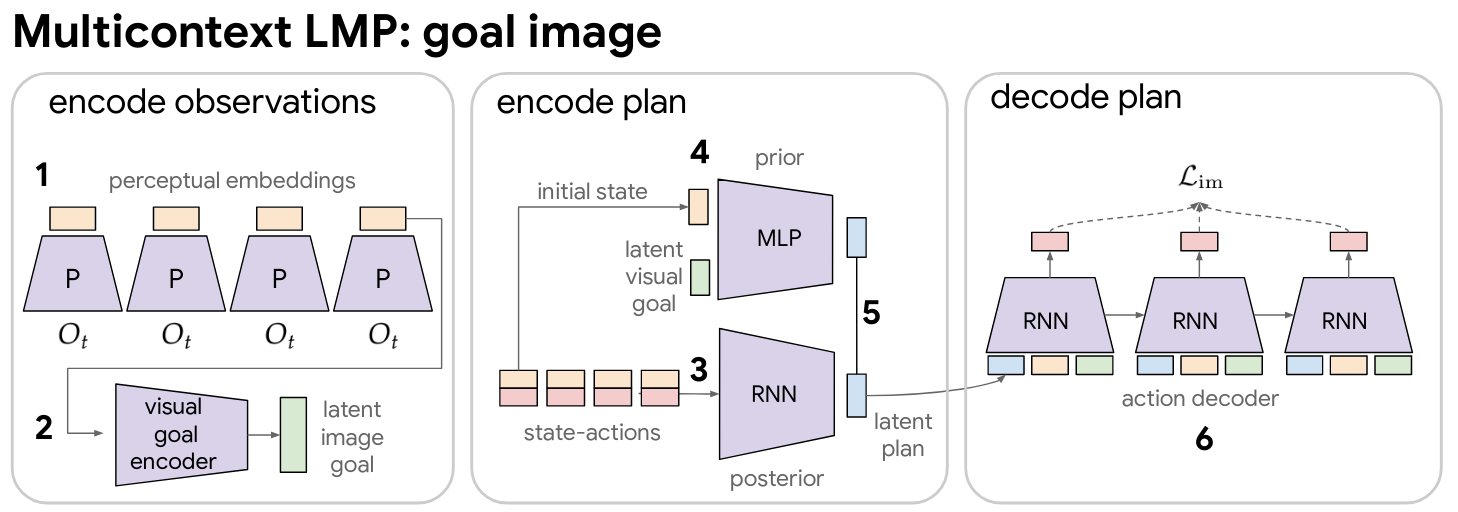 Figure 16. Latent image goal LMP: This image goal conditioned forward pass of multicontext LMP.
1) Map sequence of raw observations $O_t$ to perceptual embeddings (see Figure 9). 2) Map image goal to latent goal space. 3) Map full state-action sequence to recognized plan through posterior. 4) Map initial state and latent goal through prior network to distribution over plans for achieving goal. 5) Minimize KL divergence between posterior and prior. 6) Compute maximum likelihood action reconstruction loss by decoding plan into actions with teacher forcing. Each action prediction is conditioned on current perceptual embedding, latent image goal, and latent plan. Note perception net, posterior, prior, and policy are shared with language goal forward pass.
Figure 16. Latent image goal LMP: This image goal conditioned forward pass of multicontext LMP.
1) Map sequence of raw observations $O_t$ to perceptual embeddings (see Figure 9). 2) Map image goal to latent goal space. 3) Map full state-action sequence to recognized plan through posterior. 4) Map initial state and latent goal through prior network to distribution over plans for achieving goal. 5) Minimize KL divergence between posterior and prior. 6) Compute maximum likelihood action reconstruction loss by decoding plan into actions with teacher forcing. Each action prediction is conditioned on current perceptual embedding, latent image goal, and latent plan. Note perception net, posterior, prior, and policy are shared with language goal forward pass.
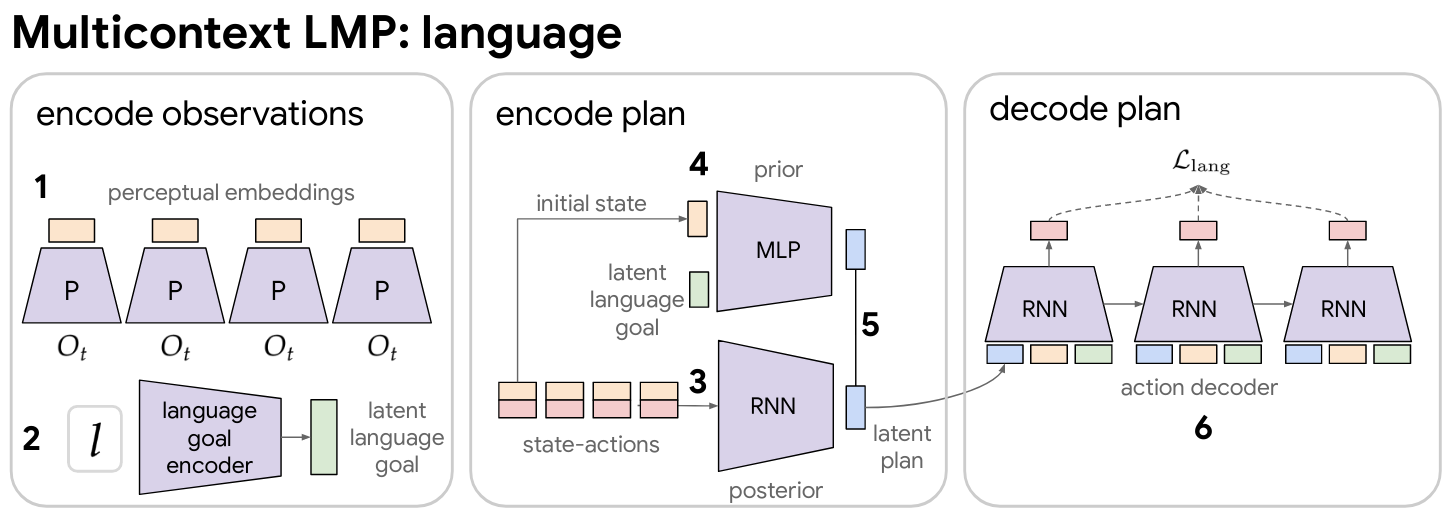 Figure 17. Latent language goal LMP: This describes the language goal conditioned forward pass of multicontext LMP. 1) Map sequence of raw observations $O_t$ to perceptual embeddings (see Figure 9). 2) Map language observation to latent goal space. 3) Map full state-action sequence to recognized plan through posterior. 4) Map initial state and latent goal through prior network to distribution over plans for achieving goal. 5) Minimize KL divergence between posterior and prior. 6) Compute maximum likelihood action reconstruction loss by decoding plan into actions with teacher forcing. Each action prediction is conditioned on current perceptual embedding, latent language goal, and latent plan. Note perception net, posterior, prior, and policy are shared with image goal LMP.
Figure 17. Latent language goal LMP: This describes the language goal conditioned forward pass of multicontext LMP. 1) Map sequence of raw observations $O_t$ to perceptual embeddings (see Figure 9). 2) Map language observation to latent goal space. 3) Map full state-action sequence to recognized plan through posterior. 4) Map initial state and latent goal through prior network to distribution over plans for achieving goal. 5) Minimize KL divergence between posterior and prior. 6) Compute maximum likelihood action reconstruction loss by decoding plan into actions with teacher forcing. Each action prediction is conditioned on current perceptual embedding, latent language goal, and latent plan. Note perception net, posterior, prior, and policy are shared with image goal LMP.
 Table 4. Training Hyperparameters.
Table 4. Training Hyperparameters.
C. Environment
We use the same simulated 3D playground environment as in , keeping the same observation and action spaces. We define these below for completeness.
C.1 Observation space
We consider two types of experiments: pixel and state experiments. In the pixel experiments, observations consist of (image, proprioception) pairs of 200x200x3 RGB images and 8-DOF internal proprioceptive state. Proprioceptive state consists of 3D cartesian position and 3D euler orientation of the end effector, as well as 2 gripper angles.
In the state experiments, observations consist of the 8D proprioceptive state, the position and euler angle
orientation of a movable block, and a continuous 1-d sensor describing: door open amount, drawer open amount, red
button pushed amount, blue button pushed amount, green button pushed amount. In both experiments, the agent additionally observes the raw string value of a natural language text channel at each timestep.
C.2 Action space
We use the same action space as : 8-DOF cartesian position, euler, and gripper angle of the end effector. Similarly, during training we quantize each action element into 256 bins. All stochastic policy outputs are represented as discretized logistic distributions over quantization bins .
D. Datasets
D.1 Play dataset
We use the same play logs collected in as the basis for all relabeled goal image conditioned learning. This consists of $\thicksim$7h of play relabeled in to $D_{\mathrm{play}}$: $\thicksim$10M short-shorizon windows, each spanning 1-2 seconds.
D.2 (Play, language) dataset
We pair 10K windows from $D_{\mathrm{play}}$ with natural language hindsight instructions using the interface shown in Figure 10 to obtain $D_{\mathrm{(play,lang)}}$. See real examples below in Table 5. Note the language collected has significant diversity in length and content.
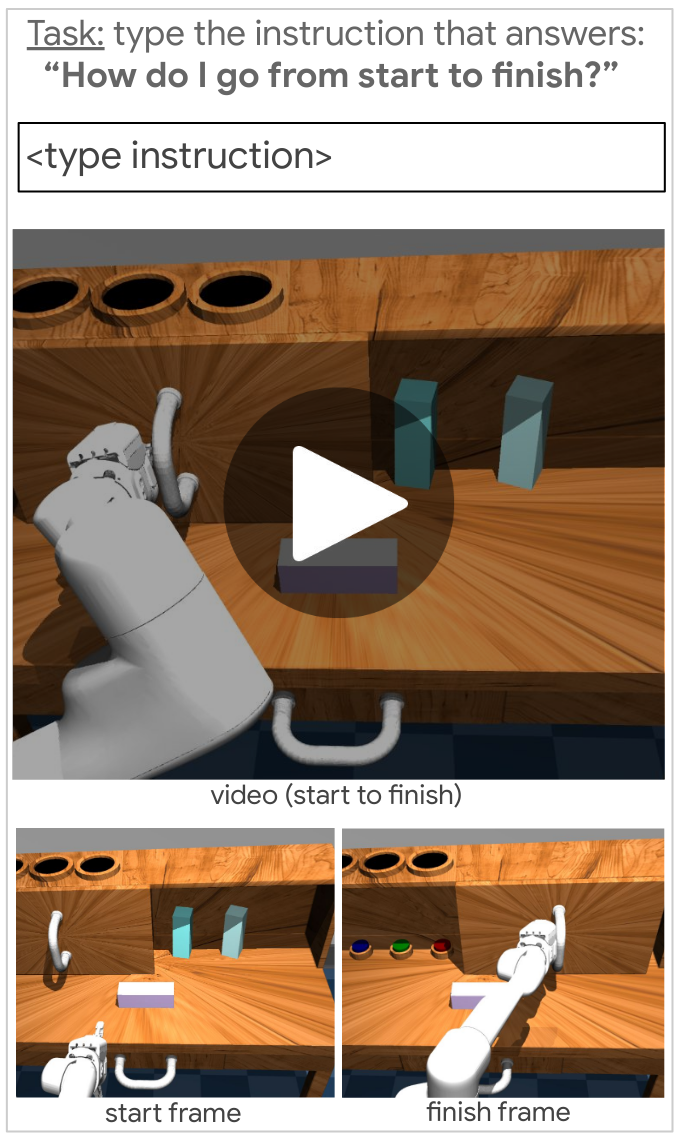 Figure 10. A schematic rendering of our hindsight language collection tool.
Figure 10. A schematic rendering of our hindsight language collection tool.
Figure 10 demonstrates how hindsight instructions are collected. Overseers are presented with a webpage that contains a looping video clip of 1 to 2 seconds of play, along with the first and the last frames of that video, to help them identify the beginning and the end of the clip if necessary.
Overseers are asked to type in a text box the sentence that best answers the question "How do I go from start to finish?".
Several considerations can go into the design of this interface. First, we can ask overseers to type in multiple instructions that are as different from each other as possible, to increase generalization and diversity of the language dataset. After experimenting with one or multiple text boxes, we opted for using only one, while asking users to write as diverse sentences as possible throughout the collection process. A disadvantage of having multiple boxes is that it can sometimes be challenging to come up with diverse sentences when the observed action is very simple. It also leads to less video-language pairs for the same budget. Thus we decided one sentence per video was most beneficial in our case.
Another collection consideration is the level of details in a sentence. For example, for a generalist robot application, it seems "open the drawer" is a more likely use case than "move your hand 10 cm to the right above the drawer handle, then grasp the drawer handle, then pull on the drawer handle". Similarly, an instruction geared toward a function such as "open the drawer" is more likely useful than one detached from it function, e.g. "put your fingers around the drawer handle, pull your hand back".
Finally, given the temporal horizon of our video clips, multiple things can be happening within one clip. How many events should be described? For example it might be important to describe multiple motions such as "close the drawer then reach for the object". With all these observations in mind, we instructed the overseers to only describe the main actions, while asking themselves: “which instructions would I give to another human being so that they could produce a similar video if they were in that scene?”.
 Table 5. Randomly sampled examples from the training set of hindsight instructions paired with play. As hindsight instruction pairing sits on top of play, the language we collect is similarly not constrained by predefined tasks, and instead covers both specific functional behaviors and general, non task-specific behaviors.
Table 5. Randomly sampled examples from the training set of hindsight instructions paired with play. As hindsight instruction pairing sits on top of play, the language we collect is similarly not constrained by predefined tasks, and instead covers both specific functional behaviors and general, non task-specific behaviors.
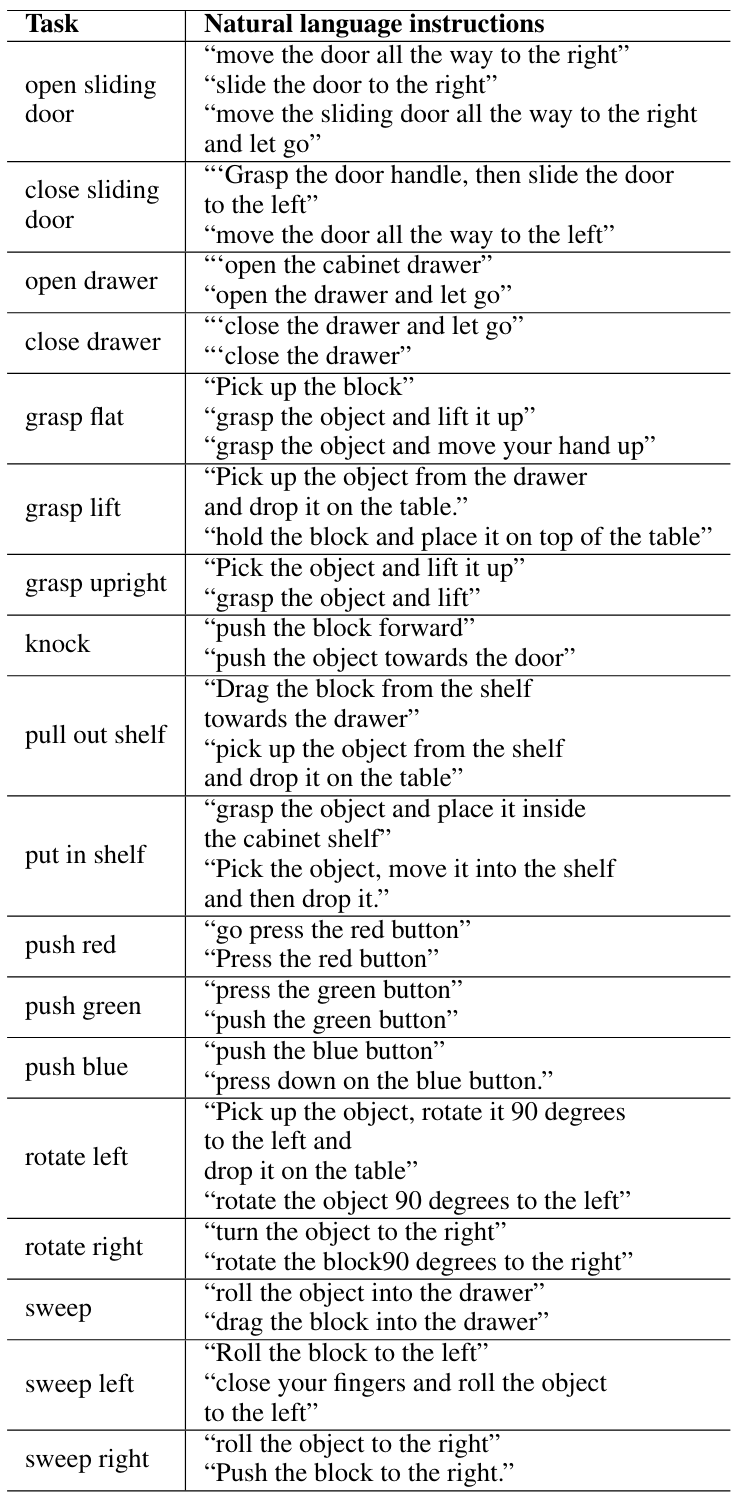 Table 6. Example natural language instructions used to specify the 18 test-time visual manipulation tasks.
Table 6. Example natural language instructions used to specify the 18 test-time visual manipulation tasks.
D.3 (Demo, language) dataset
To define $D_{\mathrm{(demo,lang)}}$, we pair each of the 100 demonstrations of the 18 evaluation tasks from with hindsight instructions using the same process as in Section 4.1. We similarly pair the 20 test time demonstrations of each of the 18 tasks. See examples for each of the tasks in Table 7.
74.3% of the natural language instructions in the test dataset appear at least once in $D_{\mathrm{play}}$.
85.08% of the instructions in $D_{\mathrm{(play,lang)}}$ never never appear in the test set.
D.4 Restricted play dataset
For a controlled comparison between LangLfP and LangBC, we train on a play dataset restricted to the same size as the aggregate multitask demonstration dataset ($\thicksim$1.5h). This was obtained by randomly subsampling the original play logs $\thicksim$7h to $\thicksim$1.5h before relabeling.
E. Models
Below we describe our various baselines and their training sources. Note that for a controlled comparison, all methods are trained using the exact same architecture described in Appendix B, differing only on the source of data.
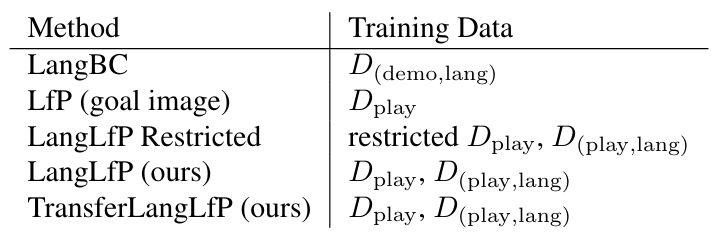 Table 7. Methods and their training data sources. All baselines are trained to maximize the same generalized contextual imitation objective MCIL.
Table 7. Methods and their training data sources. All baselines are trained to maximize the same generalized contextual imitation objective MCIL.
F. Long Horizon Evaluation
Task construction.
We construct long-horizon evaluations by considering transitions between the 18 subtasks defined in . These span multiple diverse families, e.g. opening and closing doors and drawers, pressing buttons, picking and placing a movable block, etc. For example, one of the 925 Chain-4 tasks may be "open_sliding, push_blue, open_drawer, sweep". We exclude as invalid any transitions that would result in instructions that would have necessarily already been satisfied, e.g. "open_drawer, press_red, open_drawer". To allow natural language conditioning we pair 20 test demonstrations of each subtask with human instructions using the same process as in Section 4.1 (example sentences in Table 7).
Eval walkthrough.
The long horizon evaluation happens as follows. For each of the N-stage tasks in a given benchmark, we start by resetting the scene to a neutral state. This is discussed more in the next section.
Next, we sample a natural language instruction for each task in the N-stage sequence from a test set. Next, for each subtask in a row, we condition the agent on the current subtask instruction and rollout the policy. If at any timestep the agent successfully completes the current subtask (according to the environment-defined reward), we transition to the next subtask in the sequence (after a half second delay). This attempts to mimic the qualitative scenario where a human provides one instruction after another, queuing up the next instruction, then entering it only once the human has deemed the current subtask solved. If the agent does not complete a given subtask in 8 seconds, the entire episode ends in a timeout.
We score each multi-stage rollout by the percent of subtasks completed, averaging over all multi-stage tasks in the benchmark to arrive at the final N-stage number.
Neutrality in multitask evaluation. When evaluating any context conditioned policy (goal-image, task id, natural language, etc.), a natural question that arises is: how much is the policy relying on the context to infer and solve the task? Previously in , evaluation began by resetting the simulator to the first state of a test demonstration, ensuring that the commanded task was valid. We find that under this reset scheme, the initial pose of the agent can in some cases become correlated with the task, e.g. arm nearby the drawer for a drawer opening task. This is problematic, as it potentially reveals task information to the policy through the initial state, rather than the context.
In this work, we instead reset the arm to a fixed neutral position at the beginning of every test episode. This "neutral" initialization scheme is used to run all evaluations in this paper. We note this is a fairer, but significantly more difficult benchmark. Neutral initialization breaks correlation between initial state and task, forcing the agent to rely entirely on language to infer and solve the task.
For completeness, we present evaluation curves for both LangLfP and LangBC under this and the prior possibly "correlated" initialization scheme in Figure 11. We see that when LangBC is allowed to start from the exact first state of a demonstration (a rigid real world assumption), it does well on the first task, but fails to transition to the other tasks, with performance degrading quickly after the first instruction (Chain-2, Chain-3, Chain-4). Play-trained LangLfP on the other hand, is far more robust to change in starting position, experiencing only a minor degradation in performance when switching from the correlated initialization to neutral.
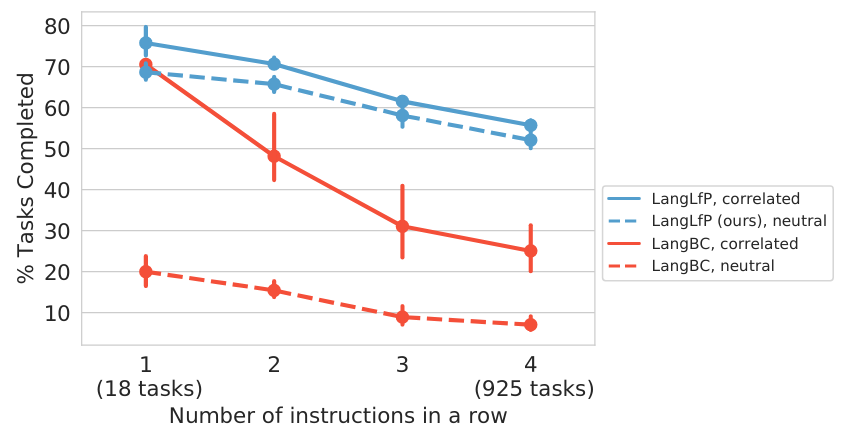 Figure 11. Training on relabeled play leads to robustness. Models trained on relabeled play (LangLfP) are robust to a fixed neutral starting position during multitask evaluation, models trained on conventional predefined demonstrations (LangBC) are not.
Figure 11. Training on relabeled play leads to robustness. Models trained on relabeled play (LangLfP) are robust to a fixed neutral starting position during multitask evaluation, models trained on conventional predefined demonstrations (LangBC) are not.
G. Qualitative Examples
Repeated Instructions
Here we demonstrate repetitions of the same pair of actions multiple times: on the left the input sentences ("pick up the object and drop it vertically", "knock the object") is are performed twice in a row, on the right the ("open the drawer", "close the drawer") instructions are repeated 3 times in a row:
|
(upright object, knock object) x 2
|
(open drawer, close drawer) x 3
|
|
object (in, out) of shelf x 2
|
|
More examples of compound instructions
H. Ablation: How much language is necessary?
We study how the performance of LangLfP scales with the number of collected language pairs. Figure 15 compares models trained from pixel inputs to models trained from state inputs as we sweep the amount of collected language pairs by factors of 2. Success is reported with confidence intervals over 3 seeded training runs. Interestingly, for models trained from states, doubling the size of the language dataset from 5k to 10k has marginal benefit on performance. Models trained from pixels, on the other hand, have yet to converge and may benefit from even larger datasets. This suggests that the role of larger language pair datasets is primarily to address the complicated perceptual grounding problem.
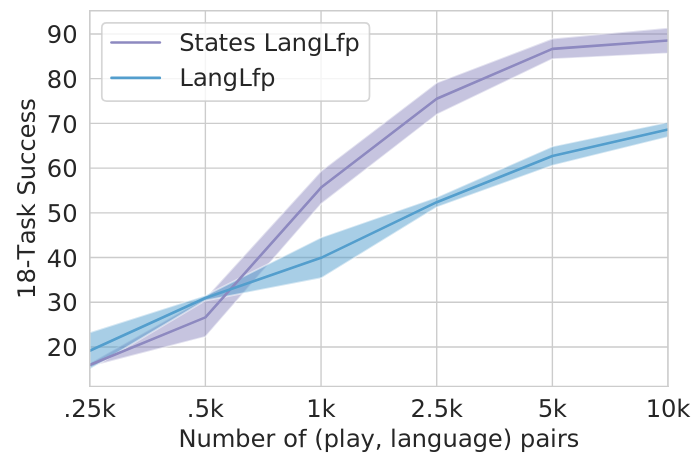 Figure 15. 18-task success vs amount of human language pairs.
Figure 15. 18-task success vs amount of human language pairs.
I. Knowledge transfer with language pretraining
TransferLangLfP, trained on top of multilingual language embeddings, is able to follow instructions in 16 different languages in zero shot. LangLfP, which learns language from scratch, can only follow English instructions it was trained on. We see when presented with cross-lingual inputs, LangLfP resorts to outputting maximum likelihood play actions. TransferLangLfP, on the other hand, correctly solves tasks.
TransferLangLfP
(understands 16 languages) |
LangLfP
(only understands english) |
|
|
|
Input sentences:
1. close the drawer all the way
2. pull the drawer handle all the way
3. drag the object into the drawer
4. close the drawer
|
|
|
|
Input sentences:
1. close the drawer all the way
2. push the door to the right
3. press green
4. move the door all the way left
|
J. More Failure Cases
The agent times out attempting to lift the block from the drawer.
The agent encounters an arm configuration likely avoided during teleoperated play, leading to compounding error.
The agent makes several incorrect choices on the way to solving a task.
Acknowledgments
We thank Karol Hausman, Eric Jang, Mohi Khansari, Kanishka Rao, Jonathan Thompson, Luke Metz, Anelia Angelova, Sergey Levine, and Vincent Vanhoucke for providing helpful feedback on this manuscript. We additionally thank the overseers for providing paired language instructions.
We thank distill.pub for providing this template.
Citation
For attribution in academic contexts, please cite this work as:
Lynch and Sermanet, "Grounding Language in Play", 2020.
BibTeX citation:
@article{lynch2021language,
title = {Language Conditioned Imitation Learning over Unstructured Data},
author = {Lynch, Corey and Sermanet, Pierre},
journal = {Robotics: Science and Systems},
year = {2021},
url = {https://arxiv.org/abs/2005.07648},
pdf = {https://arxiv.org/pdf/2005.07648.pdf},
}